
7 Proven AWS Data Analytics Strategies: The Ultimate Guide to Athena, Kinesis & Glue
Focus Keyword: AWS Data Analytics
Estimated Read Time: 25 Minutes | Author: Cloud Knowledge Expert
Table of Contents
Introduction to AWS Data Analytics
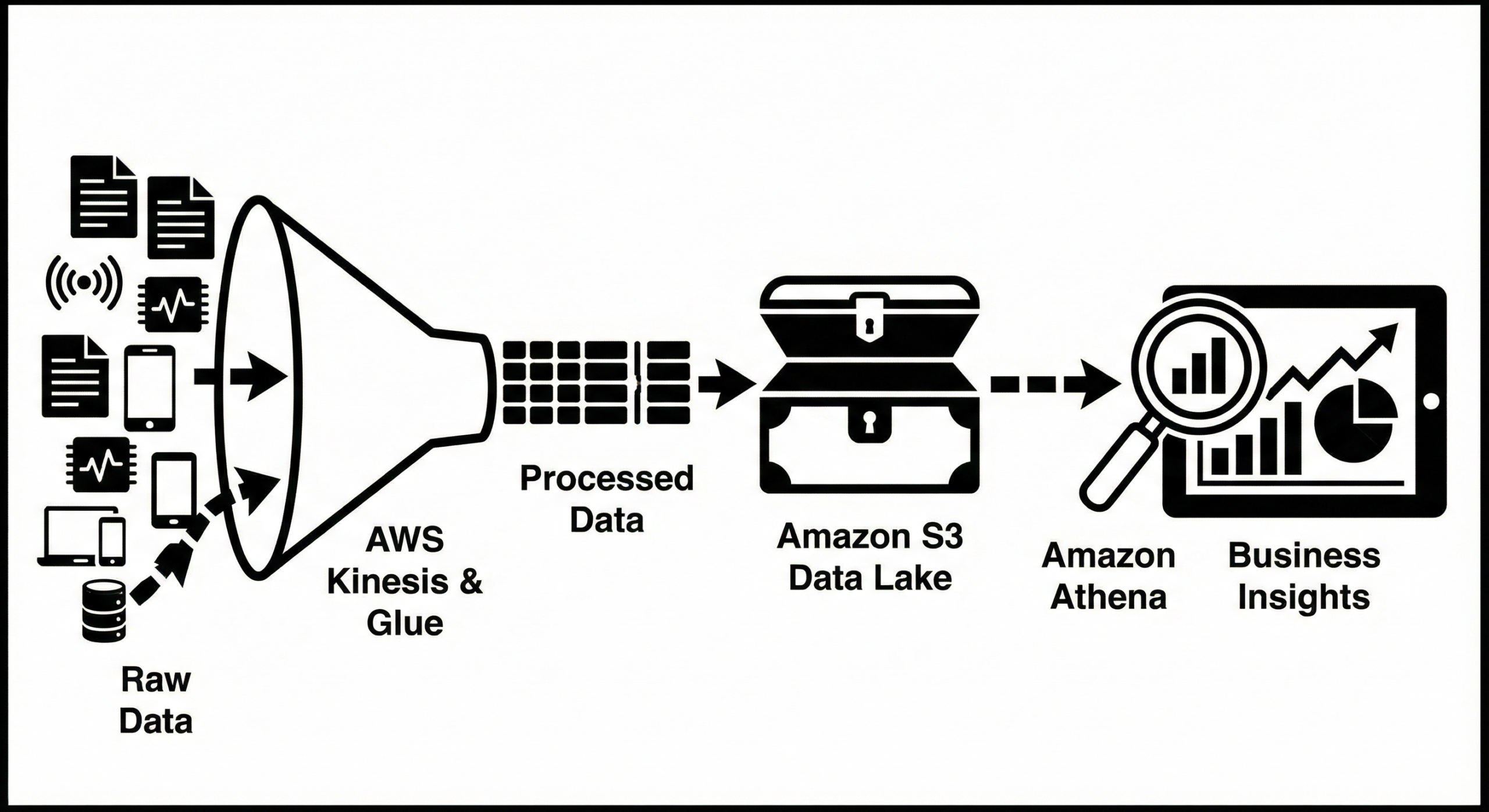
In the modern era of cloud computing, data is the new oil. However, raw data is useless without the ability to refine, process, and analyze it efficiently. This is where AWS Data Analytics services come into play. Organizations leveraging cloud technologies face the massive challenge of handling petabytes of data generated from IoT devices, application logs, and customer interactions.
AWS provides a suite of purpose-built tools designed to tackle these specific challenges. According to the official AWS Data Analytics page, these services are designed to allow you to easily build data lakes and perform analytics without managing infrastructure.
Whether you are a data engineer looking to build a data lake, a security analyst investigating security incidents, or a developer building real-time dashboards, understanding the core trio—Amazon Athena, Amazon Kinesis, and AWS Glue—is mandatory. This comprehensive guide will dissect these services, provide real-world configuration scripts, and help you master the art of cloud data analytics. We will also explore how these tools integrate with broader Microsoft and hybrid cloud architectures.
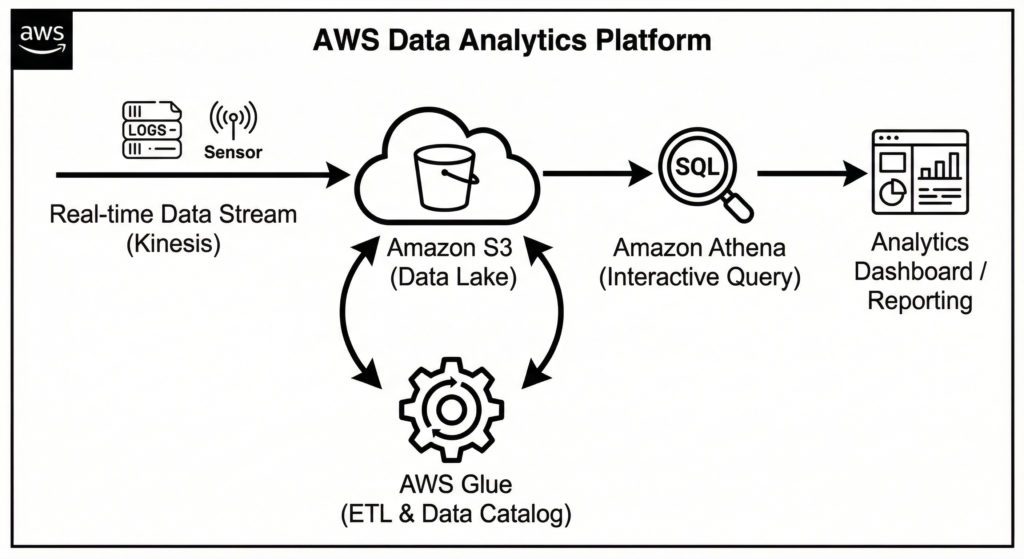
Amazon Athena: Serverless Interactive Querying

What is Amazon Athena?
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. Under the hood, Athena utilizes the Trino (formerly PrestoSQL) distributed SQL query engine, allowing for high-performance queries over vast datasets.
Top Use Cases for Athena
- Security Log Analysis: Quickly querying AWS CloudTrail logs or VPC Flow Logs to identify unauthorized access attempts. This is critical for maintaining robust cloud security posture.
- Ad-Hoc Reporting: Business intelligence teams can run one-off SQL queries on raw CSV or JSON data sitting in S3 without needing to load it into a database first.
- Cost Analysis: Querying AWS Cost and Usage Reports (CUR) to visualize spending trends.
Key Points: Amazon Athena
- Serverless: Zero infrastructure setup.
- Decoupled Storage & Compute: Data lives in S3; Athena provides the compute.
- Pricing: Charged per Terabyte (TB) of data scanned.
- Optimization: Converting data to Apache Parquet format can reduce costs by up to 90%.
Troubleshooting Athena with PowerShell
Sometimes queries hang or fail. You can use AWS Tools for PowerShell to check the status of a specific query execution ID.
# Prerequisite: Install-Module -Name AWSPowerShell
# Script to Check Athena Query Execution Status
$QueryExecutionId = "12345678-xxxx-xxxx-xxxx-xxxxxxxxxxxx"
try {
$queryInfo = Get-ATHQueryExecution -QueryExecutionId $QueryExecutionId
Write-Host "Query Status: " $queryInfo.Status.State
Write-Host "Data Scanned: " $queryInfo.Statistics.DataScannedInBytes " Bytes"
if ($queryInfo.Status.State -eq "FAILED") {
Write-Host "Error Reason: " $queryInfo.Status.StateChangeReason -ForegroundColor Red
}
}
catch {
Write-Host "Error retrieving query details: $_"
}
Amazon Kinesis: Real-Time Data Streaming

What is Amazon Kinesis?
Amazon Kinesis makes it easy to collect, process, and analyze real-time, streaming data so you can get timely insights and react quickly to new information. For technical specifications, refer to the Amazon Kinesis Documentation.
Kinesis Services Family
- Kinesis Data Streams (KDS): Highly customizable, best for building custom streaming applications.
- Kinesis Data Firehose: The easiest way to load streaming data into data stores (S3, Redshift, Splunk).
- Kinesis Video Streams: Securely stream video from connected devices to AWS for analytics and machine learning.
Use Cases
- Real-time Analytics: Powering live leaderboards for gaming applications.
- Log Ingestion: Streaming application logs from EC2 instances to an OpenSearch Service for real-time monitoring.
- IoT Data Collection: Aggregating sensor data from millions of IoT devices.
Key Points: Amazon Kinesis
- Real-Time: Enables sub-second processing latency.
- Durability: Data is replicated across three Availability Zones (AZs).
- Scalability: Throughput is managed via “Shards” (1MB/sec write per shard).
Technical Troubleshooting: Monitoring Shard Iterator Age
If your application is falling behind the stream, the “Iterator Age” metric increases. Use this AWS CLI command to inspect stream details.
# Check Kinesis Stream Details and Shard Status
aws kinesis describe-stream --stream-name "MyAnalyticsStream" --region us-east-1
# If you see "HasMoreShards": true, you may need to iterate to find all shards.
# High IteratorAgeMilliseconds in CloudWatch indicates consumers are slow.
AWS Glue: Managed ETL and Data Cataloging

What is AWS Glue?
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. It utilizes Apache Spark under the hood, allowing you to run powerful distributed processing jobs without managing the underlying cluster.
Core Components
- Data Catalog: A central metadata repository. It acts as a drop-in replacement for Hive Metastore.
- Crawlers: Automatically scan data in S3/RDS, infer schemas, and populate the Data Catalog.
- ETL Jobs: Python or Scala scripts that transform data (e.g., convert CSV to Parquet).
Use Cases
- Data Lake Management: Organizing unstructured S3 data into a structured schema usable by Athena.
- Data Preparation: Cleaning “dirty” data (removing nulls, formatting dates) before loading it into a data warehouse like Redshift.
- Hybrid Cloud Data Integration: Pulling data from on-premise databases to the cloud.
Key Points: AWS Glue
- Serverless Spark: Run powerful distributed processing without cluster management.
- Integration: Tightly integrated with Athena and Redshift Spectrum.
- Cost: Pay for DPU (Data Processing Unit) hours used.
PowerShell for Glue Job Management
Automating ETL pipelines often requires triggering jobs programmatically. Below is a PowerShell snippet to start a Glue job.
# Start an AWS Glue Job using PowerShell
$JobName = "Daily-Log-ETL-Job"
try {
$JobRun = Start-GLUEJob -JobName $JobName
Write-Host "Job Started Successfully. JobRunID: " $JobRun.JobRunId
# Check status
$Status = Get-GLUEJobRun -JobName $JobName -RunId $JobRun.JobRunId
Write-Host "Current Status: " $Status.JobRunState
}
catch {
Write-Host "Failed to start Glue Job. Error: $_"
}
Key Differentiators: Athena vs Kinesis vs Glue
Understanding when to use which service is vital for cloud architects.
| Feature | Amazon Athena | Amazon Kinesis | AWS Glue |
|---|---|---|---|
| Primary Purpose | Interactive SQL Querying | Real-Time Streaming | ETL & Data Cataloging |
| Data Latency | Batch (Query on demand) | Real-Time (Millis/Seconds) | Batch or Streaming ETL |
| Best For | Ad-hoc analysis of S3 data | Ingesting live video/logs | Preparing/Transforming data |
| Infrastructure | Serverless | Serverless / Provisioned | Serverless |
| Pricing Model | Per TB Scanned | Per Shard Hour / Put Payload | Per DPU Hour |
Frequently Asked Questions (FAQs)
1. Can Athena query data directly from Kinesis?
Not directly in real-time. Typically, Kinesis Firehose delivers data to S3, and then Athena queries that S3 data. However, for real-time SQL on streams, you would use Kinesis Data Analytics (now Managed Service for Apache Flink).
2. How do I secure my data in these services?
Security is paramount. Use IAM policies to restrict access. Ensure S3 buckets are encrypted using KMS. For detailed guidance on security best practices, refer to official AWS documentation or our internal guides.
3. Is AWS Glue cheaper than running EMR?
For sporadic or unpredictable workloads, Glue is often more cost-effective because it is serverless (no idle clusters). For constant, heavy 24/7 processing, EMR (Elastic MapReduce) with Reserved Instances might be cheaper.
4. What is the difference between Glue Data Catalog and Athena?
Athena is the query engine. Glue Data Catalog is the metadata store (database of table definitions). Athena uses the Glue Data Catalog to understand the schema of the data sitting in S3.
Leave a Reply