
Core Kubernetes Architecture: Master Node, Worker Node, Control Plane & Troubleshooting
The open-source platform Kubernetes has become the de-facto standard container orchestration system for automating deployment, scaling and management of containerised applications. In this comprehensive blog post, we’ll deep-dive into the architecture of Kubernetes: including the master/control plane, worker nodes, networking, service discovery, high availability, security, monitoring, and also provide PowerShell/Graph API style examples (for Azure AKS or other managed clusters) for troubleshooting. As part of this we’ll link to our site CloudKnowledge.in for internal anchors and link out to authoritative external resources. This blog is SEO-optimised for visibility in Microsoft Edge News, Google Discover and Bing—with clear headings, keywords, and structured content.
Table of Contents
- Overview of Kubernetes Architecture
- Master Node vs Worker Node
- Control Plane Components
- Worker Node Components
- Pods and Deployments
- Cluster Networking
- Service Discovery & Load Balancing
- Namespaces & Resource Isolation
- High Availability (HA) Control Plane
- Kubernetes Security
- Kubernetes API Communication Flow
- Cluster Monitoring & Logging
- Troubleshooting Examples & Scripts
- Conclusion
Overview of Kubernetes Architecture
The platform we know as Kubernetes (often abbreviated “K8s”) is designed to automate deployment, scaling, and operations of containerised applications. At its core, Kubernetes uses a declarative configuration model and desired-state management: you declare what you want, and Kubernetes works to make the actual state match the declared desired state.
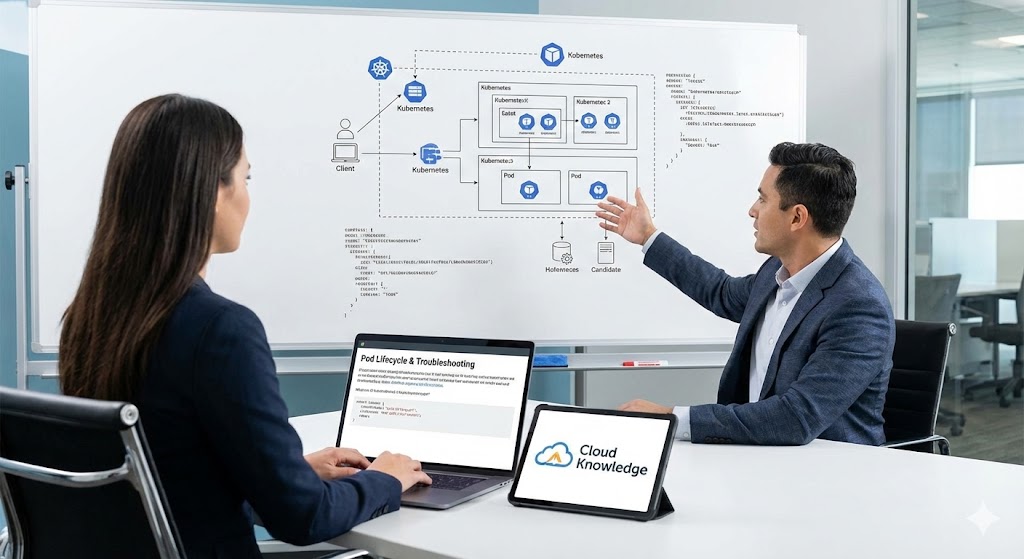
A Kubernetes cluster is comprised of a **control plane** (also called the master node layer) and one or more **worker nodes** where the application workloads run. The control plane is responsible for global decisions about the cluster (for example scheduling), and the worker nodes run the containers and pods. This separation enables scalability, resilience, and automation.
The declarative model means you submit manifests (YAML/JSON) describing e.g. “I want 3 replicas of this deployment running”, and Kubernetes ensures via its reconciliation loop that the actual number of pods match that. That automation and orchestration is the value proposition of Kubernetes for scalable microservices architecture.
Master Node vs Worker Node
Understanding the difference between the master (control plane) and worker (data plane) nodes is critical for both architecture design and troubleshooting.
Control Plane (Master Node)
The control plane manages the cluster — schedules workloads, maintains state, and handles cluster-level operations. All the heavy decision-making logic resides here. In many managed offerings (e.g., AKS, EKS, GKE) the control plane is abstracted, but the underlying components remain the same.
Worker Nodes
Worker nodes host application containers. They run agents (such as kubelet & kube-proxy) and a container runtime (like containerd or CRI-O). The control plane assigns work to the worker nodes.
In simple terms: think of the control plane as the brain (or the “master”), and the worker nodes as the muscles doing the work.
Control Plane Components
Let’s break down the key components of the control plane, their roles, and why they matter.
kube-apiserver
The kube‑apiserver is the central management interface of the cluster. All REST API calls (including via kubectl, dashboards, external controllers) pass through the API server. It validates and configures data for the API objects which represent the desired state of the cluster.
etcd
The etcd key-value store is the single source of truth for the cluster’s state. It stores configuration, metadata, and the current state of all API objects. It must be highly available and consistent for the cluster to function correctly.
kube-scheduler
The kube‑scheduler watches for unscheduled pods and assigns them to nodes based on resource requirements, policies, node health, and constraints like affinity/anti-affinity.
kube-controller-manager
The kube‑controller‑manager runs a set of controllers that monitor the shared state of the cluster and make changes based on that: for example ReplicaSetController, EndpointsController, NodeController. It ensures the actual state matches the desired state.
cloud-controller-manager
The cloud‑controller‑manager integrates Kubernetes with the underlying cloud provider (if present) to manage load-balancers, storage volumes, networking and other vendor-specific services. This allows the core Kubernetes components to remain cloud-agnostic while delegating cloud tasks to this controller.
Why this separation matters
By modularising the control plane, Kubernetes enables extensibility, fault tolerance, and clear responsibilities. For example, etcd handles state persistence, while the API server delegates to scheduler & controllers for decision-making.
Worker Node Components
On each worker node (sometimes called “minion” in older docs) the following key components run:
kubelet
The kubelet is an agent that runs on each worker node. It receives PodSpecs from the API server and ensures the containers described are running and healthy. It registers the node with the control plane and reports status.
kube-proxy
The kube‑proxy manages networking rules on the node. It maintains network connectivity to pods, implements Service abstraction (forwarding, load-balancing) and ensures routing within-cluster and to external endpoints.
Container Runtime
The container runtime is the underlying software that actually runs containers. Examples include containerd, CRI‑O, and historically Docker (though dockershim is deprecated).
Pods and Deployments
In Kubernetes the building blocks of application workloads are:
- Pod – the smallest deployable unit in Kubernetes. A Pod may contain one or more containers that share network namespace and storage volumes.
- Deployment – a higher-level abstraction that provides declarative updates, rolling updates, replication, self-healing and versioning of Pods.
When you create a Deployment, you specify a desired state (for example: run 5 replicas of nginx:1.23). The Deployment controller ensures that state is maintained (e.g., if a Pod fails, a new one is created). This is a core part of Kubernetes’ “desired state” architecture.
Cluster Networking
Networking in Kubernetes is complex and fundamental: Pods need to communicate with each other, Services need to expose Pods, and external traffic may need to ingress the cluster. Key topics include:
CNI (Container Network Interface)
The CNI framework allows third-party network plugins (like Calico, Flannel, Cilium) to provide Pod-to-Pod connectivity and manage networking policies. Kubernetes supports pluggable network models.
Pod-to-Pod communication
Each Pod gets its own IP address. Pods can communicate with other Pods (across nodes) subject to network policy and plugin constraints. The cluster network must allow this flat network unless restricted by policy.
Service Networking
Services abstract a group of Pods (via label selectors) and provide a stable endpoint (IP/DNS) for clients. The networking model supports ClusterIP, NodePort, LoadBalancer and Ingress. We’ll cover Service types in the next section.
Service Discovery & Load Balancing
To expose workloads and allow communication, Kubernetes offers the following service types:
- ClusterIP – the default. Exposes the Service only inside the cluster.
- NodePort – exposes the Service on each Node’s IP at a static port.
- LoadBalancer – provisioned by cloud providers to expose the Service externally via a load-balancer.
- Ingress – manages external HTTP/HTTPS routing to Services within the cluster.
These abstractions enable flexible exposure of workloads and manage traffic routing inside and outside the cluster. Documentation emphasises this as part of Kubernetes' service discovery mechanism.
Namespaces & Resource Isolation
Namespaces provide logical segmentation within a cluster. They help with:
- Multi-tenancy (different teams or environments share same cluster).
- Resource quotas and limit ranges per namespace.
- Access-control boundaries (via RBAC) at namespace scope.
Using namespaces correctly is a best practice for large scale clusters and helps drive isolation, governance and cost management.
High Availability (HA) Control Plane
In production environments you’ll typically deploy multiple control-plane nodes (masters) with replicated etcd to avoid a single point of failure (SPOF). Key considerations for HA include:
- Etcd must be configured as an odd-number cluster (3,5,7) for quorum.
- API Servers are load-balanced (external LB or internal VIP) so clients always hit a healthy endpoint.
- Controller & Scheduler components may run as active/passive or active/active depending on architecture.
- Worker nodes should detect control plane failure and optionally failover or reschedule workloads accordingly.
Achieving HA also means paying attention to latency, networking, and consistent storage across control-plane nodes.
Kubernetes Security
Security is a major domain in Kubernetes operations. Key topics include:
RBAC (Role-Based Access Control)
The RBAC system allows granular permissioning to Kubernetes API objects. For secure clusters, only required permissions should be granted (least-privilege).
Network Policies
Using CNI-capable network policies you can restrict traffic between Pods, namespaces, and external endpoints — enforcing “zero-trust” style segmentation inside the cluster.
Secrets Management
The Secrets API object stores sensitive information such as passwords, tokens and keys. Ensure encryption at rest, access control and proper lifecycle management.
Pod Security Standards (PSS)
Recent versions introduce Pod Security Standards (PSA) to enforce runtime policy—such as disallowing privileged containers, root mounts, host-network use etc.
Given the critical nature of production workloads, combining RBAC, network policies, secrets encryption and secure runtime settings forms the core of a hardened Kubernetes cluster strategy.
Kubernetes API Communication Flow
Understanding how a simple command flows through the architecture helps in troubleshooting:
- An operator runs `kubectl apply -f deployment.yaml`. The client contacts the API Server (`kube-apiserver`).
- API Server authenticates/authorises request, accepts the desired-state object into etcd.
- The Scheduler watches for unscheduled Pods and assigns them to appropriate Node(s).
- The Controller Manager watches the state via API server and triggers replication, scaling, or healing.
- The selected Worker Node’s kubelet watches the API server for work assigned to that node, pulls the container image via the container runtime, and ensures the Pod launches.
- kube-proxy on the node sets up networking rules so the Pod can be reached either internally (ClusterIP) or externally (Ingress/LoadBalancer).
- Node status/heartbeat is sent back to the control-plane (via kubelet) and stored in etcd; if nodes fail, controllers reschedule workloads.
Having this flow in mind helps when you see “Pod Pending”, “Image Pull BackOff”, “Node Not Ready” — you can trace which layer is failing.
Cluster Monitoring & Logging
To maintain healthy clusters and troubleshoot issues, monitoring and logging are essential. Typical stack includes:
- Metrics & Monitoring: Tools like Prometheus + Grafana collect cluster/node/pod metrics (CPU, memory, disk, network). Alerts can be set on threshold violations.
- Logging: Aggregated logs via ELK Stack (Elasticsearch, Logstash, Kibana) or other platforms capture container stdout/stderr, kubelet logs, control-plane logs etc.
- Tracing: For microservices, distributed tracing (e.g., Jaeger) helps pinpoint latency across services/pods.
Monitoring and logging let administrators detect anomalies (node pressure, pod restarts, network latency) and act proactively rather than only reacting to failures.
Troubleshooting Examples & Scripts
Below are sample troubleshooting commands and a sample script (PowerShell for Azure-AKS or Graph API approach) to inspect cluster health.
kubectl & cluster health checks
# Check nodes and their status
kubectl get nodes -o wide
# Check pods in all namespaces for errors
kubectl get pods --all-namespaces
# Check events for recent failures
kubectl get events --sort-by='.metadata.creationTimestamp' -A
PowerShell snippet (Azure AKS) to inspect control-plane and node health
# Login to Azure and set context
Connect-AzAccount
$aks = Get-AzAksCluster -ResourceGroup "MyRG" -Name "MyAKS"
# Retrieve node resource status
Get-AzAksNodePool -ResourceGroup "MyRG" -ClusterName "MyAKS" | ForEach-Object {
$_.Name; Get-AzVM -ResourceGroupName $_.ResourceGroupName -Name $_.VmName | Select-Object Name, PowerState
}
# Inspect control-plane health (via Kubernetes API)
kubectl get componentstatuses
Graph API (for Azure AD & AKS integrated clusters) approach
In environments where your cluster uses Azure AD for identity and you have automation via Graph API, you might query service principal assignments, role assignments, or Kubernetes RBAC bindings to ensure correct access and no mis-configuration causing failures.
// Example (pseudo) Graph API call to list role assignments for AKS cluster
GET https://graph.microsoft.com/v1.0/roleAssignments?$filter=resourceId eq ''
Common issues & resolution checklist
- Node NotReady → Inspect `kubectl describe node
` for kubelet/kube-proxy failures, check CPU/memory pressure, docker/containerd failure. - Pod Pending → Check scheduler events: `kubectl describe pod`, maybe node has insufficient resources or taints/affinities preventing scheduling.
- ImagePullBackOff → Check container registry access, image name/tag mismatch, network access from node.
- Service Unreachable → Check kube-proxy rules, service endpoints via `kubectl get endpoints`, network policy blocking, CNI plugin issues.
- Control Plane degraded** → Check etcd cluster health: `etcdctl endpoint health`, ensure quorum and latency okay. API server logs for errors.
Conclusion
Understanding the architecture of Kubernetes — from the control plane to worker nodes, from networking to security to observability — is essential if you are designing, operating, or troubleshooting production-grade clusters. The declarative model and desired-state management underpin how Kubernetes delivers scaling, self-healing, and flexibility.
For further reading and deeper dives, explore articles on CloudKnowledge.in, and the official documentation at Kubernetes Architecture.
Whether you’re an engineer, architect or DevOps practitioner, mastering these core themes — master vs worker separation, control-plane components, networking, service discovery, namespaces, HA, security, monitoring, and troubleshooting flows — gives you the confidence to build resilient, scalable container platforms that underpin modern cloud-native applications.
Happy orchestrating!

Your article helped me a lot, is there any more related content? Thanks! https://accounts.binance.com/ru-UA/register-person?ref=JVDCDCK4