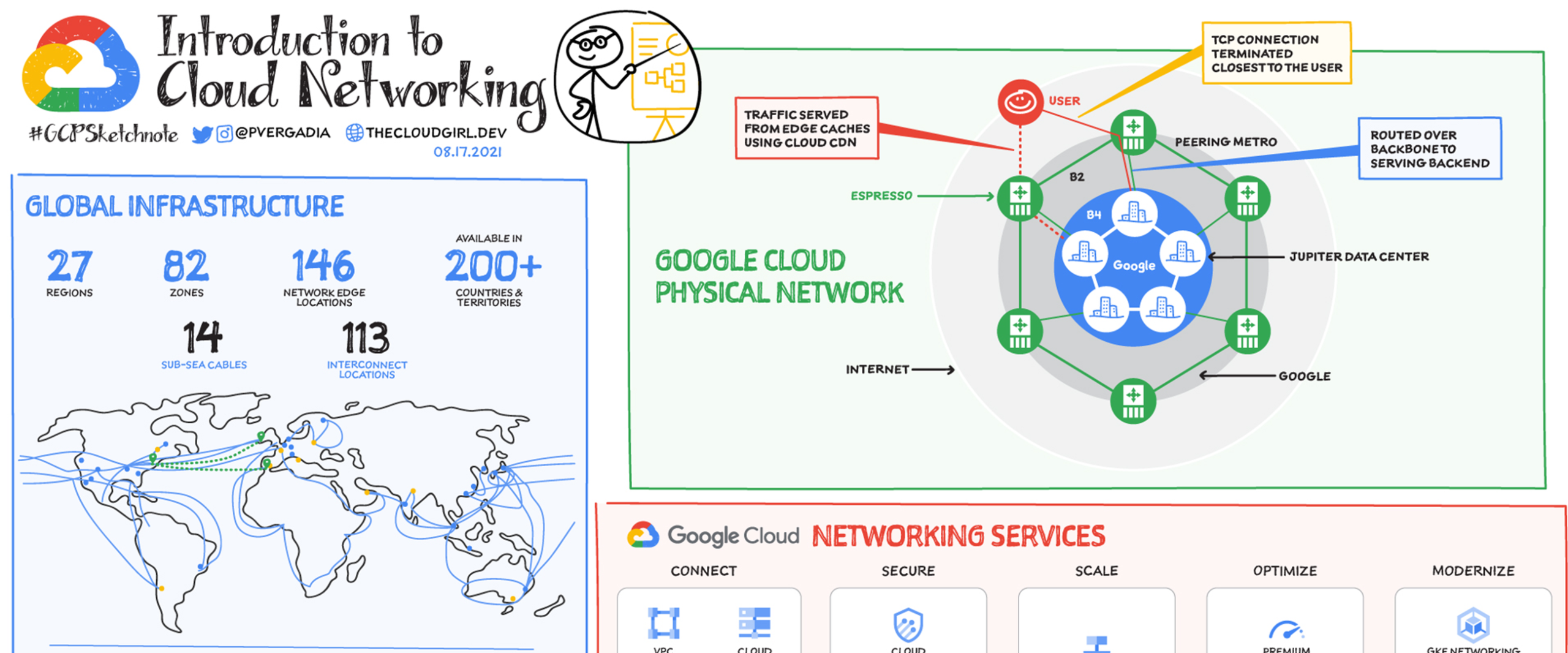
GCP Compute Services & Google Kubernetes Engine (GKE)
Last updated: November 1, 2025 • Written for engineering leaders, architects, SREs, and platform teams.
What you’ll get: A hands-on, production-grade tour of Google Cloud compute—covering
Google Compute Engine (GCE) virtual machines,
Google Kubernetes Engine (GKE) for containers,
Cloud Run and App Engine for serverless,
with autoscaling, load balancing, security, pricing, and troubleshooting scripts (gcloud, kubectl, and PowerShell for Google Cloud).
Overview of GCP Compute Services
Google Cloud Platform provides a spectrum of compute choices so teams can match workload shape to the right operational model:
- Virtual machines with Google Compute Engine (GCE) for maximum flexibility and lift-and-shift scenarios.
- Containers on Google Kubernetes Engine (GKE) for portable, declarative microservices with automated orchestration.
- Serverless with Cloud Run and App Engine to run stateless apps and APIs with scale-to-zero and no cluster management.
Across these, GCP layers autoscaling, Cloud Load Balancing, managed VPC networking, deep IAM, security primitives like Shielded and Confidential VMs, and integrated Observability via Cloud Monitoring and Cloud Logging.
Google Compute Engine (GCE): Virtual Machines Done Right
GCE offers customizable Linux/Windows VMs to host monoliths, stateful databases, line-of-business apps, and batch or HPC jobs. Core value:
- Machine families & types: General-purpose (e2, n2), Compute-optimized (c2), Memory-optimized (m2), and specialized shapes with GPUs/TPUs.
- Custom machine types: Dial exact vCPU and memory to avoid over-provisioning.
- Preemptible/Spot VMs: Short-lived, deeply discounted capacity perfect for fault-tolerant and batch workloads.
- Instance groups: Managed Instance Groups (MIGs) with autoscaling, regional distribution, and autohealing via health checks.
- Security: IAM integration, Shielded VMs, Confidential VMs, OS patch management, VPC-level firewalling, and Private Service Access.
Quick start: create a VM with gcloud
# Create a minimal e2-medium VM in a specific zone
gcloud compute instances create app-vm-1 \
--zone=us-central1-a \
--machine-type=e2-medium \
--image-family=debian-12 \
--image-project=debian-cloud \
--tags=http-server,https-server
# Open firewall for HTTP/HTTPS (VPC network firewall rule)
gcloud compute firewall-rules create allow-http-https \
--allow tcp:80,tcp:443 \
--target-tags=http-server,https-server
PowerShell for Google Cloud (Windows & CI/CD friendly)
If you prefer PowerShell, Google provides a set of cmdlets (“Google Cloud Tools for PowerShell”). After installing the Google Cloud SDK and modules, you can manage GCE similarly to gcloud.
# Install Google Cloud SDK first, then PowerShell modules (if not present)
# In PowerShell (run as Administrator as needed):
# Authenticate (opens browser)
gcloud auth login
# Set project
gcloud config set project <YOUR_PROJECT_ID>
# Example: list instances via gcloud from PowerShell
gcloud compute instances list
# Using the Google Cloud .NET/PowerShell cmdlets (if installed):
# Get-GceInstance, New-GceInstance, etc. Example pattern:
# New-GceInstance -Project <PROJECT> -Zone us-central1-a -Name "app-vm-1" -MachineType "e2-medium" -ImageFamily "debian-12" -ImageProject "debian-cloud"
# Troubleshooting: fetch serial port output for a failed boot
gcloud compute instances get-serial-port-output app-vm-1 --zone us-central1-a
Troubleshooting GCE:
- Boot issues? Check
get-serial-port-output and confirm OS login settings (OS Login/IAM roles).
- No external connectivity? Verify VPC routes, NAT, and firewall rules (ingress/egress).
- Autoscaling not triggering? Confirm MIG metrics, health checks, and target utilization.
Google Kubernetes Engine (GKE): Managed Kubernetes for Modern Apps
GKE is Google’s battle-tested managed Kubernetes. You get a managed control plane, node auto-provisioning, Surge Upgrades, Autopilot mode, multi-zonal/regional clusters, and tight integration with Artifact Registry, Cloud Logging, and Cloud Monitoring.
Cluster creation (Standard vs Autopilot)
# Standard cluster (you manage node pools)
gcloud container clusters create gke-standard-1 \
--zone=us-central1-a \
--machine-type=e2-standard-4 \
--num-nodes=3 \
--enable-ip-alias \
--release-channel=regular
# Autopilot cluster (fully managed nodes, pay per pod)
gcloud container clusters create-auto gke-autopilot-1 \
--region=us-central1 \
--release-channel=regular
Deploy a sample workload
# Get kubeconfig
gcloud container clusters get-credentials gke-autopilot-1 --region us-central1
# Simple deployment + service
kubectl create deploy hello --image=us-docker.pkg.dev/cloudrun/container/hello
kubectl expose deploy hello --type=LoadBalancer --port=80 --target-port=8080
# Watch external IP
kubectl get svc hello -w
Upgrade strategy
- Release channels: Rapid/Regular/Stable. Choose Regular/Stable for prod.
- Surge upgrades & max surge: Avoid outages during node image/K8s upgrades.
- Node auto-provisioning: Let GKE create right-sized node pools on demand.
GKE Troubleshooting Playbook (kubectl, gcloud, API)
# 1) Pod crashloop? Inspect logs & events
kubectl logs deploy/hello --tail=200
kubectl describe pod $(kubectl get pod -l app=hello -o name)
# 2) Network/connectivity issues?
kubectl get svc,ep -A
kubectl get networkpolicy -A
# 3) Node pressure or scheduling failures?
kubectl describe node <NODE_NAME>
kubectl get events -A --sort-by=.lastTimestamp | tail -n 50
# 4) GKE control plane & node pool health
gcloud container clusters describe gke-autopilot-1 --region us-central1
gcloud container node-pools list --cluster gke-autopilot-1 --region us-central1
Call the GKE API directly (useful in automation)
# Get cluster details via REST (using gcloud to obtain an access token)
ACCESS_TOKEN=$(gcloud auth print-access-token)
PROJECT_ID=<YOUR_PROJECT_ID>
LOCATION=us-central1
CLUSTER=gke-autopilot-1
curl -s -H "Authorization: Bearer ${ACCESS_TOKEN}" \
"https://container.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/clusters/${CLUSTER}" | jq .
PowerShell automation for GKE (kubectl/gcloud from PS)
# In PowerShell, you can orchestrate gcloud/kubectl for pipelines
$ErrorActionPreference = "Stop"
$project = "<YOUR_PROJECT_ID>"
$region = "us-central1"
$cluster = "gke-autopilot-1"
# Ensure auth & context
gcloud config set project $project
gcloud container clusters get-credentials $cluster --region $region
# Health checks
kubectl get nodes
kubectl get pods -A
kubectl get events -A --sort-by=.lastTimestamp | Select-Object -Last 50
# Rollout with verification
kubectl set image deploy/hello hello=us-docker.pkg.dev/cloudrun/container/hello:2.0
kubectl rollout status deploy/hello --timeout=120s
Best practice: Prefer Autopilot for platform simplicity and cost transparency; choose Standard when you need DaemonSets, privileged workloads, or custom node images.
Autoscaling & Cloud Load Balancing
GCP’s autoscaling adjusts capacity horizontally (pods/VMs) while Cloud Load Balancing distributes global traffic with Anycast IPs, health checks, and advanced routing.
Horizontal Pod Autoscaler (HPA) on GKE
# Create an HPA targeting 70% CPU for the 'hello' deployment
kubectl autoscale deploy hello --cpu-percent=70 --min=2 --max=20
# Observe scaling
kubectl get hpa -w
MIG Autoscaling on GCE
# Create a MIG template and attach autoscaling based on CPU utilization
gcloud compute instance-templates create web-tmpl \
--machine-type=e2-standard-4 \
--image-family=debian-12 \
--image-project=debian-cloud \
--tags=http-server
gcloud compute instance-groups managed create web-mig \
--base-instance-name=web \
--size=2 \
--template=web-tmpl \
--zone=us-central1-a
gcloud compute instance-groups managed set-autoscaling web-mig \
--zone=us-central1-a \
--max-num-replicas=20 \
--target-cpu-utilization=0.65 \
--cool-down-period=60
Global HTTP(S) Load Balancer
# High-level steps (using gcloud). In practice you'll define backend service, URL map, target proxy, forwarding rule.
# 1) Create health check
gcloud compute health-checks create http hc-basic --port 80
# 2) Backend service referencing MIG
gcloud compute backend-services create web-bes \
--protocol=HTTP --port-name=http --health-checks=hc-basic --global
gcloud compute backend-services add-backend web-bes \
--instance-group=web-mig --instance-group-zone=us-central1-a --global
# 3) URL map, target proxy, forwarding rule (Anycast)
gcloud compute url-maps create web-map --default-service=web-bes
gcloud compute target-http-proxies create web-proxy --url-map=web-map
gcloud compute forwarding-rules create web-fr \
--global --target-http-proxy=web-proxy --ports=80
Serverless Compute: Cloud Run
Cloud Run runs stateless containers without cluster management. It scales to zero, bills per request+time, and integrates with VPC, IAM, Pub/Sub, and Eventarc.
Deploy to Cloud Run
# Build and deploy a container to Cloud Run
gcloud builds submit --tag us-central1-docker.pkg.dev/<PROJECT>/apps/hello:v1 .
gcloud run deploy hello \
--image us-central1-docker.pkg.dev/<PROJECT>/apps/hello:v1 \
--region us-central1 \
--allow-unauthenticated \
--memory 512Mi --cpu 1 --max-instances 50
When to choose Cloud Run vs GKE? Pick Cloud Run for simple stateless services and event-driven APIs with bursty or unpredictable traffic. Choose GKE when you need multi-service meshes, sidecars, custom admission controllers, or heavy stateful operators.
App Engine: PaaS for Web Apps & APIs
App Engine provides a fully managed platform with automatic scaling, versions, and traffic splitting. Standard environment offers fast scale-to-zero on language sandboxes; Flexible runs in containers on Compute Engine VMs.
Quick sample (Python, Standard)
# app.yaml
runtime: python312
handlers:
- url: /.*
script: auto
# Deploy
gcloud app create --region=us-central
gcloud app deploy
gcloud app browse
Preemptible & Spot VMs: Slash Batch Costs
Preemptible/Spot instances deliver deep discounts for fault-tolerant work like media rendering, CI runners, ML training with checkpointing, and ETL. Use instance templates and MIGs with multiple instance types to improve availability.
Example: Preemptible Node Pool for GKE
gcloud container node-pools create spot-pool \
--cluster=gke-standard-1 \
--zone=us-central1-a \
--machine-type=e2-standard-4 \
--num-nodes=0 \
--enable-autoscaling --min-nodes=0 --max-nodes=50 \
--spot
VM Families & Custom Machine Types
# Create a minimal e2-medium VM in a specific zone
gcloud compute instances create app-vm-1 \
--zone=us-central1-a \
--machine-type=e2-medium \
--image-family=debian-12 \
--image-project=debian-cloud \
--tags=http-server,https-server
# Open firewall for HTTP/HTTPS (VPC network firewall rule)
gcloud compute firewall-rules create allow-http-https \
--allow tcp:80,tcp:443 \
--target-tags=http-server,https-server
# Install Google Cloud SDK first, then PowerShell modules (if not present)
# In PowerShell (run as Administrator as needed):
# Authenticate (opens browser)
gcloud auth login
# Set project
gcloud config set project <YOUR_PROJECT_ID>
# Example: list instances via gcloud from PowerShell
gcloud compute instances list
# Using the Google Cloud .NET/PowerShell cmdlets (if installed):
# Get-GceInstance, New-GceInstance, etc. Example pattern:
# New-GceInstance -Project <PROJECT> -Zone us-central1-a -Name "app-vm-1" -MachineType "e2-medium" -ImageFamily "debian-12" -ImageProject "debian-cloud"
# Troubleshooting: fetch serial port output for a failed boot
gcloud compute instances get-serial-port-output app-vm-1 --zone us-central1-a
- Boot issues? Check
get-serial-port-outputand confirm OS login settings (OS Login/IAM roles). - No external connectivity? Verify VPC routes, NAT, and firewall rules (ingress/egress).
- Autoscaling not triggering? Confirm MIG metrics, health checks, and target utilization.
# Standard cluster (you manage node pools)
gcloud container clusters create gke-standard-1 \
--zone=us-central1-a \
--machine-type=e2-standard-4 \
--num-nodes=3 \
--enable-ip-alias \
--release-channel=regular
# Autopilot cluster (fully managed nodes, pay per pod)
gcloud container clusters create-auto gke-autopilot-1 \
--region=us-central1 \
--release-channel=regular
# Get kubeconfig
gcloud container clusters get-credentials gke-autopilot-1 --region us-central1
# Simple deployment + service
kubectl create deploy hello --image=us-docker.pkg.dev/cloudrun/container/hello
kubectl expose deploy hello --type=LoadBalancer --port=80 --target-port=8080
# Watch external IP
kubectl get svc hello -w
# 1) Pod crashloop? Inspect logs & events
kubectl logs deploy/hello --tail=200
kubectl describe pod $(kubectl get pod -l app=hello -o name)
# 2) Network/connectivity issues?
kubectl get svc,ep -A
kubectl get networkpolicy -A
# 3) Node pressure or scheduling failures?
kubectl describe node <NODE_NAME>
kubectl get events -A --sort-by=.lastTimestamp | tail -n 50
# 4) GKE control plane & node pool health
gcloud container clusters describe gke-autopilot-1 --region us-central1
gcloud container node-pools list --cluster gke-autopilot-1 --region us-central1
# Get cluster details via REST (using gcloud to obtain an access token)
ACCESS_TOKEN=$(gcloud auth print-access-token)
PROJECT_ID=<YOUR_PROJECT_ID>
LOCATION=us-central1
CLUSTER=gke-autopilot-1
curl -s -H "Authorization: Bearer ${ACCESS_TOKEN}" \
"https://container.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/clusters/${CLUSTER}" | jq .
# In PowerShell, you can orchestrate gcloud/kubectl for pipelines
$ErrorActionPreference = "Stop"
$project = "<YOUR_PROJECT_ID>"
$region = "us-central1"
$cluster = "gke-autopilot-1"
# Ensure auth & context
gcloud config set project $project
gcloud container clusters get-credentials $cluster --region $region
# Health checks
kubectl get nodes
kubectl get pods -A
kubectl get events -A --sort-by=.lastTimestamp | Select-Object -Last 50
# Rollout with verification
kubectl set image deploy/hello hello=us-docker.pkg.dev/cloudrun/container/hello:2.0
kubectl rollout status deploy/hello --timeout=120s
# Create an HPA targeting 70% CPU for the 'hello' deployment
kubectl autoscale deploy hello --cpu-percent=70 --min=2 --max=20
# Observe scaling
kubectl get hpa -w
# Create a MIG template and attach autoscaling based on CPU utilization
gcloud compute instance-templates create web-tmpl \
--machine-type=e2-standard-4 \
--image-family=debian-12 \
--image-project=debian-cloud \
--tags=http-server
gcloud compute instance-groups managed create web-mig \
--base-instance-name=web \
--size=2 \
--template=web-tmpl \
--zone=us-central1-a
gcloud compute instance-groups managed set-autoscaling web-mig \
--zone=us-central1-a \
--max-num-replicas=20 \
--target-cpu-utilization=0.65 \
--cool-down-period=60
# High-level steps (using gcloud). In practice you'll define backend service, URL map, target proxy, forwarding rule.
# 1) Create health check
gcloud compute health-checks create http hc-basic --port 80
# 2) Backend service referencing MIG
gcloud compute backend-services create web-bes \
--protocol=HTTP --port-name=http --health-checks=hc-basic --global
gcloud compute backend-services add-backend web-bes \
--instance-group=web-mig --instance-group-zone=us-central1-a --global
# 3) URL map, target proxy, forwarding rule (Anycast)
gcloud compute url-maps create web-map --default-service=web-bes
gcloud compute target-http-proxies create web-proxy --url-map=web-map
gcloud compute forwarding-rules create web-fr \
--global --target-http-proxy=web-proxy --ports=80
# Build and deploy a container to Cloud Run
gcloud builds submit --tag us-central1-docker.pkg.dev/<PROJECT>/apps/hello:v1 .
gcloud run deploy hello \
--image us-central1-docker.pkg.dev/<PROJECT>/apps/hello:v1 \
--region us-central1 \
--allow-unauthenticated \
--memory 512Mi --cpu 1 --max-instances 50
# app.yaml
runtime: python312
handlers:
- url: /.*
script: auto
# Deploy
gcloud app create --region=us-central
gcloud app deploy
gcloud app browse
gcloud container node-pools create spot-pool \
--cluster=gke-standard-1 \
--zone=us-central1-a \
--machine-type=e2-standard-4 \
--num-nodes=0 \
--enable-autoscaling --min-nodes=0 --max-nodes=50 \
--spot
| Family | Use Case | Notes |
|---|---|---|
| General-purpose (e2, n2) | Web apps, APIs, microservices | Balanced CPU/memory, cost-efficient. |
| Compute-optimized (c2) | CPU-heavy, high QPS | Great for game servers, encoding, gateways. |
| Memory-optimized (m2) | In-memory DB, analytics | Large RAM footprints, caching tiers. |
| GPU/TPU | Training/inference, HPC | Pair with AI/ML toolchains. |
With custom machine types, tune vCPU and memory for fine-grained optimization and combine with committed use contracts for significant savings.
GPUs & TPUs for AI/ML
Attach NVIDIA GPUs to GCE or enable GPU node pools in GKE. TPUs accelerate large-scale training on TensorFlow/JAX. For inference, consider Cloud Run with CPU for light models, or GPU-backed GKE for heavier latency-sensitive inference.
GPU node pool (GKE)
gcloud container node-pools create gpu-pool \
--cluster gke-standard-1 \
--zone us-central1-a \
--accelerator type=nvidia-l4,count=1 \
--machine-type n2-standard-8 \
--num-nodes 1
Instance Groups & Autohealing
MIGs restart unhealthy instances, balance across zones, and integrate with load balancers and autoscaling policies.
# Enable health checks and autohealing on a MIG
gcloud compute health-checks create http hc-web --port 80
gcloud compute instance-groups managed update web-mig \
--zone us-central1-a \
--health-check hc-web \
--initial-delay 120
Compute Engine Security, IAM, and Compliance
- IAM: Use least privilege roles and service accounts per workload; rotate keys and prefer Workload Identity.
- Shielded VMs: Secure boot and vTPM protect against firmware/rootkit attacks.
- Confidential VMs: Memory encryption for in-use data.
- Networking: VPC firewalls, hierarchical policies, Private Google Access, VPC Service Controls.
Security checks (scripts)
# List which service account is on each instance
gcloud compute instances list --format="table(name,zone,serviceAccounts[].email.list())"
# Enumerate open firewall rules in the project
gcloud compute firewall-rules list --format="table(name,direction,disabled,allowed,denied,sourceRanges.list())"
Regional & Zonal Deployments for Resilience
Design for failure by spreading across zones (zonal outages) and regions (geo redundancy). GKE regional clusters replicate control plane/components; GCE regional MIGs distribute traffic. Use Cloud DNS and global load balancing for fast failover.
Hybrid & Multi-Cloud with Anthos
Anthos manages Kubernetes across GCP, on-prem, and other clouds. You get consistent policy (Config Management), service mesh (Anthos Service Mesh), and fleet-wide observability.
Cloud Functions Integration (Event-Driven)
Cloud Functions lets you run lightweight functions on events (Pub/Sub, Storage, HTTP). Use it to glue systems, enrich events, or call microservices running in GKE/Cloud Run.
Container & Artifact Registries
Store and secure images in Artifact Registry (preferred) or Container Registry (legacy). Enforce binary authorization, vulnerability scanning, and least-privilege pull permissions (per-service account).
# Push image to Artifact Registry
gcloud artifacts repositories create apps --repository-format=docker --location=us-central1
gcloud auth configure-docker us-central1-docker.pkg.dev
docker build -t us-central1-docker.pkg.dev/<PROJECT>/apps/api:v1 .
docker push us-central1-docker.pkg.dev/<PROJECT>/apps/api:v1
Resource Management & Monitoring
The Operations Suite (Monitoring/Logging/Trace/Profile) gives SREs deep visibility. Export logs to BigQuery for analytics or to Pub/Sub for pipelines.
Observability quick wins
- Enable GKE workload logging/metrics; ship application logs with structured fields.
- Alert on SLO burn rates and golden signals (latency, errors, saturation, traffic).
- Use Uptime checks + Notification Channels (email, Slack, PagerDuty).
# Create a basic uptime check against a load balancer endpoint (gcloud example)
gcloud monitoring uptime check-configs create \
--display-name="hello-lb" \
--http-check-path="/" \
--resource-type=uptime-url \
--selected-regions=usa,asia \
--period=60s \
--timeout=10s \
--http-check-port=80 \
--monitored-resource-labels host="<PUBLIC_DNS_OR_IP>"
Networking for Compute
Design your VPC with explicit subnets, hierarchical firewall policies, Private Google Access, VPC peering/SC, and NAT for egress. Use Private Service Connect for private producer/consumer patterns.
VPC essentials checklist
- Separate subnets by environment (dev/test/prod) and workload sensitivity.
- Centralized egress via Cloud NAT; deny 0.0.0.0/0 ingress unless explicitly required.
- Use service perimeters (VPC Service Controls) for data exfiltration protection.
Pricing & Cost Optimization
- Sustained-use & committed-use discounts: Commit to baseline usage for large savings.
- Right-size with custom machine types: Trim idle memory/CPU.
- Leverage Recommenders: Rightsizing, idle resources, abandoned IPs, image cleanup.
- Use Spot/Preemptible for batch: Shift CI, rendering, ETL to spot pools.
- Autopilot GKE: Pay per pod; avoid paying for idle nodes.
Cost guardrails (command snippets)
# List idle external IPs
gcloud compute addresses list --filter="status=RESERVED" --format="table(name,address,region)"
# Find unattached persistent disks
gcloud compute disks list --filter="-users:*" --format="table(name,sizeGb,type,zone)"
# GKE: find underutilized workloads (requests >> usage)
kubectl top pods -A
kubectl get deployments -A -o json | jq '.items[] | {ns:.metadata.namespace, name:.metadata.name, cpuReq:.spec.template.spec.containers[].resources.requests.cpu, memReq:.spec.template.spec.containers[].resources.requests.memory}'
Hands-On Troubleshooting Cookbook (Copy-Paste Ready)
1) My GKE service has no external IP
# Confirm service type and events
kubectl get svc hello -o wide
kubectl describe svc hello
# Check if cluster has a working LB controller and quota
gcloud compute forwarding-rules list
gcloud compute backend-services list
gcloud compute health-checks list
# Ensure your Service is type=LoadBalancer or use an Ingress with HTTP(S) LB
2) Pods are Pending due to insufficient resources
# See scheduler events and resource requests
kubectl describe pod PENDING_POD
kubectl get nodes -o wide
kubectl describe nodes | egrep -i "Insufficient|taints"
# Fixes:
# - Lower requests/limits or adjust resource classes
# - Enable node auto-provisioning or scale node pool
3) Cloud Run responds 403 to unauthenticated users
# Allow unauthenticated access explicitly
gcloud run services add-iam-policy-binding hello \
--region us-central1 \
--member="allUsers" \
--role="roles/run.invoker"
4) MIG not scaling
gcloud compute instance-groups managed describe web-mig --zone us-central1-a
gcloud compute instance-groups managed get-autoscaler web-mig --zone us-central1-a
gcloud compute backend-services get-health web-bes --global
5) VM startup scripts failing
# Inspect startup-script logs
gcloud compute instances get-serial-port-output app-vm-1 --zone us-central1-a | more
# Or write logs to Stackdriver by echoing to /var/log/startupscript.log
DevSecOps Pipelines: Build Once, Run Anywhere
- Build images with Cloud Build; sign and scan in Artifact Registry.
- Promote via tags; deploy to GKE/Cloud Run/App Engine using GitOps (Config Sync/ArgoCD).
- Policy as code: Binary Authorization, admission controls, and OPA/Gatekeeper.
# Example Cloud Build trigger step for GKE rollout (cloudbuild.yaml fragment)
steps:
- name: gcr.io/cloud-builders/kubectl
args: ["rollout","restart","deployment/hello"]
env: ["CLOUDSDK_COMPUTE_REGION=us-central1","CLOUDSDK_CONTAINER_CLUSTER=gke-autopilot-1"]
Use Cases & Best Practices
Microservices on GKE
- Namespace per team/app; NetworkPolicies for east-west isolation.
- Use Workload Identity for cloud API access; avoid long-lived keys.
- Enable HPA and PodDisruptionBudgets; set liveness/readiness probes.
- Adopt a service mesh for retries, mTLS, and policy once your app count grows.
AI Model Training on GCE with GPUs
- Choose GPU family (L4, A100) for your framework and batch size.
- Use Spot for non-critical batches with checkpointing to GCS.
- Pin drivers & CUDA versions; bake an image for reproducibility.
Web Hosting on App Engine
- Use versions and traffic splitting for safe canaries.
- Set instance class and min/max instances for latency control.
- Protect secrets with Secret Manager + runtime env injection.
Operational Runbooks (PowerShell & gcloud)
Rotate container image across environments (PowerShell orchestration)
# Variables
$project = "<PROJECT>"
$region = "us-central1"
$cluster = "gke-autopilot-1"
$image = "us-central1-docker.pkg.dev/$project/apps/hello:v2"
# Login
gcloud config set project $project
gcloud container clusters get-credentials $cluster --region $region
# Update image & verify
kubectl set image deploy/hello hello=$image
kubectl rollout status deploy/hello --timeout=180s
# Smoke test
$svc = kubectl get svc hello -o json | ConvertFrom-Json
$ip = $svc.status.loadBalancer.ingress[0].ip
Invoke-WebRequest -Uri ("http://{0}/" -f $ip) -UseBasicParsing
Project hygiene sweep (PowerShell)
# Find unattached disks and stale static IPs
gcloud compute disks list --filter="-users:*" --format="table(name,zone,sizeGb)"
gcloud compute addresses list --filter="status=RESERVED" --format="table(name,address,region)"
Export logs for a namespace (kubectl + gcloud)
# Tail logs for a namespace and save locally
$ns = "prod"
kubectl logs -n $ns --selector=app=hello --tail=200 --all-containers > hello-prod.log
# Copy to Cloud Storage (ensure gsutil is configured)
gsutil cp hello-prod.log gs://<BUCKET>/logs/hello-prod-$(date +%F).log
Migration Guidance: Picking the Right Compute
| Workload | Recommended Service | Why |
|---|---|---|
| Monolith with stateful DB | GCE + Regional MIG + LB | Full OS control & predictable scaling. |
| Microservices | GKE (Autopilot or Standard) | Declarative ops, service mesh, autoscaling. |
| Event-driven APIs | Cloud Run | Scale-to-zero, per-request billing, simple ops. |
| Simple web/API PaaS | App Engine | Built-in versions, traffic split, fast scale. |
| Batch/ETL/CI runners | Spot VMs or GKE spot pools | Massive savings with fault-tolerance. |
| ML training/inference | GCE/GKE with GPU/TPU | Hardware acceleration, flexible topology. |
Security & Compliance Checklist
- Enforce org policies (disable external IPs by default; restrict service account key creation).
- Adopt Workload Identity everywhere (GKE & Cloud Run) to replace secret keys.
- Binary Authorization and image attestations before prod deploy.
- Enable CMEK for data stores as needed; rotate secrets with Secret Manager.
- Log sinks to restricted BigQuery datasets; set retention & access controls.
Reliability Patterns
- Blue/Green & Canary: App Engine traffic split; GKE canary Deployments with
maxUnavailable: 0. - Regional everything: Use multi-zone node pools; regional MIGs + global LBs.
- Chaos testing: Validate HPA, PDBs, and readiness during failure injections.
Governance, Quotas, and Limits
Set folder-level quotas and budgets; alert when nearing limits (e.g., forwarding rules, backend services, CPU quotas). Use organization policies to block risky services at the root and allowlist only what teams need.
Putting It All Together: A Production Blueprint
Platform Foundation
- Org Policies, folders, projects per environment.
- Hub-and-spoke VPCs, Shared VPC, Cloud NAT, Private Google Access.
- Centralized identity via IAM + Workload Identity Federation.
App Runtime
- GKE Autopilot for microservices; GCE for statefuls; Cloud Run for edge APIs.
- Artifact Registry with scanning + Binary Authorization gates.
- Global HTTP(S) LB with Cloud Armor for WAF/rate limiting.
Observability
- Structured logs; SLOs; Uptime checks; on-call runbooks.
- Export logs to BigQuery; dashboards in Cloud Monitoring.
FinOps
- Budgets & alerts per project.
- Committed use discounts; right-sizing weekly reviews.
- Decommission idle IPs/disks; schedule non-prod shutdowns.
Conclusion
Google Cloud’s compute stack—GCE, GKE, Cloud Run, and App Engine—lets you meet any workload with the right operational trade-offs. Pair global load balancing and autoscaling for performance, apply strong IAM and Shielded/Confidential VMs for security, and use Observability with FinOps to keep reliability high and costs in check. The scripts and runbooks above should give you a practical starting point to build, troubleshoot, and scale with confidence.
© CloudKnowledge — Educational content only. Validate commands in a non-production environment first.