Compute Services — Compute Engine: Virtual Machines (VMs) with Customizable CPU, Memory, and GPU
A practical, field-tested guide to designing, operating, and troubleshooting Compute Engine virtual machines with right-sized vCPU, RAM, and accelerators.
1) Introduction to Compute Engine
Compute Engine is the core IaaS service that lets you provision Linux and Windows virtual machines on Google Cloud. You get on-demand elasticity, predictable performance, strong security primitives, and deep integration with the platform’s networking, storage, and observability stack. The secret to sustainable performance and cost is customization: matching CPU, memory, and GPU/TPU exactly to your workload profile, then automating lifecycle with templates, instance groups, and policy.
- Scale single instances or entire fleets across regions and zones.
- Mix predefined and custom machine types for fine-grained right-sizing.
- Attach Persistent Disk or ultra-fast Local SSD.
- Use MIGs for self-healing & autoscaling; front with global load balancing.
- Enforce IAM, VPC firewalls, Confidential VMs, and Shielded VMs.
2) Fully Customizable Machine Types
Right-size for performance and cost: define exact vCPU and RAM, choose CPU platform (Intel/AMD/ARM), and toggle accelerators per instance or per template. Customization eliminates underutilization and prevents hidden throttling due to overcommit on the guest OS.
3) Predefined & Custom Families
- Predefined: Standard (balanced), High-CPU, High-Memory families.
- Custom: Set precise vCPU (e.g., 10) and memory (e.g., 40 GiB). Perfect for niche services, JVMs, and memory-bound analytics.
4) Acceleration: GPUs & TPUs
Add NVIDIA GPUs (T4, L4, A100, H100, etc.) or attach TPUs for AI/ML training, rendering, or visualization. Isolate training from inference with separate instance groups so scaling signals don’t clash.
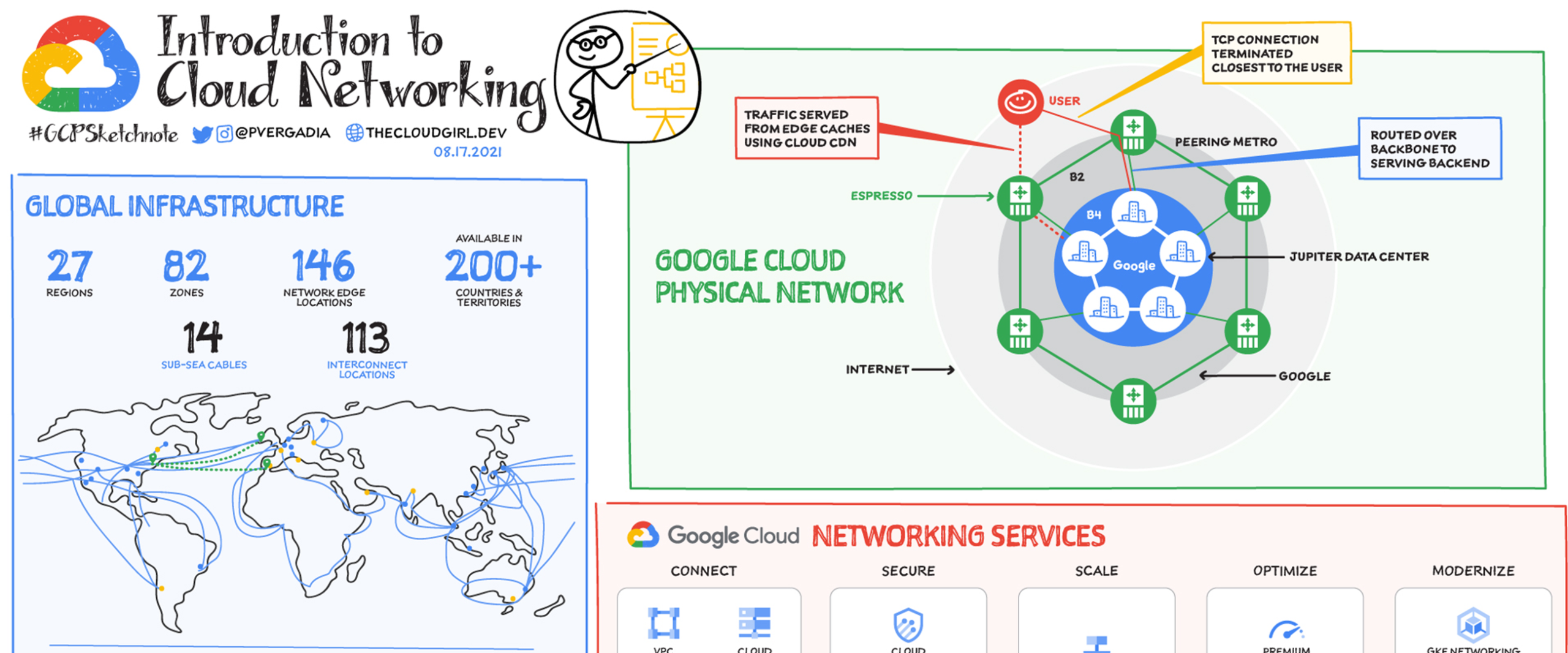
5) Global Infrastructure & Availability
Deploy across regions and zones to reduce latency and improve resilience. Regional MIGs distribute capacity across zones; multi-region designs mitigate disasters. Keep state durable on Persistent Disk and replicate where appropriate.
6) Autoscaling & Load Balancing
Autoscaling adds/removes instances based on CPU, HTTP request rate, custom metrics, or queue depth. Pair MIGs with global Load Balancers to route users to the nearest healthy backend and absorb failover automatically.
7) Security & Compliance
- At-rest encryption by default; customer-managed keys optional.
- VPC firewall rules, hierarchical policies, and organization constraints.
- IAM roles and service accounts enforce least privilege for APIs and runtime access.
- Confidential VMs (hardware memory encryption) & Shielded VMs (Secure Boot, vTPM, integrity monitoring).
8) Disks: Persistent, Balanced/SSD, & Local SSD
- Standard PD (HDD): cost-optimized throughput for archival/batch.
- Balanced/SSD PD: low latency & high IOPS for databases and APIs.
- Local SSD: ultra-fast ephemeral storage for scratch/indices.
9) Preemptible & Spot VMs
Slash compute spend with Spot/Preemptible instances (fault-tolerant batch, CI, rendering). Run interrupt-safe workloads and checkpoint progress to Cloud Storage or PD.
10) Management & Automation
- Console UI for quick operations and debugging.
- gcloud CLI for repeatable scripts.
- Terraform / Deployment Manager for IaC pipelines.
- REST/JSON APIs for programmatic orchestration.
11) Networking & Connectivity
- Design VPC with custom subnets and secondary ranges.
- Private Google Access, Cloud NAT, Cloud Router for egress control.
- Hybrid via Cloud VPN or Dedicated/Partner Interconnect.
12) Identity & Access Control
- Service accounts scoped to minimal API access.
- OS Login centralizes SSH/RDP authorization.
- Identity-Aware Proxy (IAP) for zero-trust TCP/HTTP access.
13) Billing & Cost Optimization
- Sustained-use discounts and committed-use contracts.
- Right-sizing recommendations via Monitoring.
- Budgets, alerts, and export for chargeback/FinOps.
14) Instance Templates & Managed Instance Groups
Capture VM specs (machine, image, disks, metadata) in a Template; deploy via MIGs that self-heal, roll, and scale by policy. Use regional MIGs for zonal resilience.
15) Monitoring & Logging
- Cloud Monitoring (CPU, mem, disk, network, custom metrics).
- Cloud Logging (serial console, syslog, Windows Event logs with agent).
- Error Reporting, Trace, and Profiler to reduce latency and noise.
16) OS Images & Custom Images
- Public: Debian, Ubuntu, Rocky, Windows Server, RHEL, SUSE, Container-Optimized OS.
- Bring your own images; harden with CIS baselines.
17) Performance Optimization
- Select CPU platform (Intel/AMD/ARM) matched to instruction needs (AVX-512, etc.).
- High-throughput networking (up to 100 Gbps) with placement policies.
- Shielded VMs + kernel tuning for consistent latency.
18) Live Migration & Maintenance
Live migration moves VMs across hosts during maintenance with near-zero downtime. For ultra-sensitive services, combine MIG surge/batch policies with connection draining.
19) Integrations with Google Cloud Services
- BigQuery for analytical offload.
- Cloud Storage for immutable artifacts and datasets.
- Cloud SQL for managed relational backends.
- GKE for containerized microservices with VM backends.
- Vertex AI for ML training/inference pipelines.
20) Use Cases & Best Practices
- Web/app servers behind global load balancers.
- ML training with GPU pools; autoscale by queue depth.
- Batch ETL and scientific compute on Spot capacity.
- Rendering/simulation with Local SSD scratch.
- Hybrid extensions with private connectivity and IAM federation.
Design Blueprints (Right-Sizing Patterns)
A) API Microservice (Latency-Sensitive)
- Custom 2–4 vCPU, 4–8 GiB RAM; SSD PD; COS/Ubuntu.
- MIG autoscale on 95th percentile latency & CPU.
- Global HTTP(S) Load Balancer; connection draining on rollouts.
B) JVM/Memory-Heavy Service
- Custom 8–16 vCPU with 1:8–1:12 vCPU:RAM ratio.
- NUMA pinning where applicable; GC tuned; SSD PD.
- Regional MIG; surge=20%, batch=10% for rolling updates.
C) GPU Training Cluster
- A100/H100 with large CPU memory headroom.
- Placement policies for low-latency east-west traffic.
- Preemptible GPU nodes for cheap hyper-parameter sweeps.
D) Windows Line-of-Business App
- 4–8 vCPU, 16–32 GiB RAM; Balanced PD.
- OS Login + IAP for RDP; Cloud Logging for Event Viewer ingestion.
- Budget alerts + sustained-use discounts.
Day-2 Operations: Runbooks & Commands
Provision a Custom VM (gcloud)
# Create a custom VM with 10 vCPU and 40 GiB RAM
gcloud compute instances create api-custom-01 \
--zone=us-central1-a \
--machine-type=custom-10-40960 \
--image-family=ubuntu-2204-lts --image-project=ubuntu-os-cloud \
--boot-disk-type=pd-ssd --boot-disk-size=50 \
--tags=api-service --service-account=my-sa@proj.iam.gserviceaccount.com \
--scopes=https://www.googleapis.com/auth/cloud-platformAttach an NVIDIA GPU
# Add a T4 GPU to a VM (requires compatible image/driver)
gcloud compute instances create trainer-01 \
--zone=us-central1-a \
--machine-type=n1-standard-8 \
--accelerator=type=nvidia-tesla-t4,count=1 \
--maintenance-policy=TERMINATE \
--image-family=ubuntu-2204-lts --image-project=ubuntu-os-cloudInstance Template & Regional MIG
# Create instance template
gcloud compute instance-templates create web-tmpl \
--machine-type=e2-standard-4 \
--image-family=cos-stable --image-project=cos-cloud \
--boot-disk-type=pd-balanced --boot-disk-size=20
# Create a regional MIG from the template
gcloud compute instance-groups managed create web-mig \
--template=web-tmpl \
--size=2 \
--region=us-central1
# Autoscale on CPU
gcloud compute instance-groups managed set-autoscaling web-mig \
--region=us-central1 --min-num-replicas=2 --max-num-replicas=20 \
--target-cpu-utilization=0.65REST: Create a VM (JSON)
# Example curl (use a valid OAuth2 token in $TOKEN)
curl -X POST \
-H "Authorization: Bearer $TOKEN" \
-H "Content-Type: application/json" \
https://compute.googleapis.com/compute/v1/projects/PROJECT/zones/us-central1-a/instances \
-d '{
"name": "rest-vm-01",
"machineType": "zones/us-central1-a/machineTypes/custom-6-24576",
"disks": [{
"boot": true,
"initializeParams": {"sourceImage": "projects/ubuntu-os-cloud/global/images/family/ubuntu-2204-lts","diskType":"zones/us-central1-a/diskTypes/pd-balanced","diskSizeGb":"40"}
}],
"networkInterfaces": [{"network":"global/networks/default"}],
"tags": {"items": ["rest-api"]},
"serviceAccounts": [{"email":"my-sa@proj.iam.gserviceaccount.com","scopes":["https://www.googleapis.com/auth/cloud-platform"]}]
}'Terraform: Minimal VM
provider "google" {
project = var.project
region = "us-central1"
}
resource "google_compute_instance" "vm" {
name = "tf-vm-01"
zone = "us-central1-a"
machine_type = "custom-4-8192"
boot_disk {
initialize_params {
image = "projects/ubuntu-os-cloud/global/images/family/ubuntu-2204-lts"
size = 30
type = "pd-ssd"
}
}
network_interface {
network = "default"
access_config {}
}
tags = ["terraform","demo"]
}Deep Troubleshooting Guide (VM, OS, Network, Storage)
1) VM Won’t Boot
- Check serial console logs (gcloud compute instances get-serial-port-output VM).
- Use diagnostic disk method: detach boot disk, attach to helper VM, fix fstab/grub/drivers, reattach.
- For Windows, verify VirtIO/SCSI drivers and disable problematic startup services offline.
2) CPU or Memory Spikes
- Confirm right-sizing; consider custom machine type or vertical scale (stop → change → start).
- Enable agents for guest metrics; correlate spikes with deploys/traffic patterns.
- For JVM/.NET, tune GC and thread pools; pin large caches to Local SSD if ephemeral is OK.
3) Disk Latency/IOPS Issues
- Verify PD type (Standard vs Balanced vs SSD) matches IOPS needs; increase size to raise PD performance caps.
- Align filesystem and queue settings; mount options noatime,discard where appropriate.
- Use Local SSD for scratch/indices and keep persistent state on PD.
4) Network Throughput & Drops
- Check MTU end-to-end; for VPN/Interconnect, ensure MSS clamping.
- Placement policy for chatty east-west traffic; scale out instead of up for noisy neighbor isolation.
- Profile with iperf3; enable receive-side scaling and tune kernel buffers.
5) Autoscaling Doesn’t Trigger
- Confirm metric source (CPU vs custom) and policy thresholds.
- Health checks must reflect user-visible readiness; avoid shallow TCP checks for complex apps.
- Use warm-up durations for JIT/heap priming workloads.
6) Windows Guest: Rapid Troubleshooting with PowerShell
These PowerShell snippets run inside the Windows VM to speed up diagnosis (they don’t rely on external index/disallowed tags or Graph APIs):
CPU/Memory Top Talkers
# Top 10 processes by CPU (last 30s)
Get-Process | Sort-Object CPU -Descending | Select-Object -First 10 `
| Select-Object ProcessName,Id,CPU,PM,WS | Format-Table -AutoSize
# Live CPU per process (sample 10 times)
1..10 | ForEach-Object {
Get-Counter '\Process(*)\% Processor Time' | Select-Object -ExpandProperty CounterSamples `
| Sort-Object CookedValue -Descending | Select-Object -First 10 | ForEach-Object {
'{0,-30} {1,8:N1}%' -f $_.InstanceName,$_.CookedValue
}
Start-Sleep -Seconds 3
}Disk Latency & Queueing
# Identify disks with high latency and queue length
Get-Counter '\PhysicalDisk(*)\Avg. Disk sec/Read','\PhysicalDisk(*)\Avg. Disk sec/Write','\PhysicalDisk(*)\Current Disk Queue Length' `
| Select-Object -ExpandProperty CounterSamples | Sort-Object CookedValue -Descending | Select-Object -First 20Network Errors & Drops
# NIC error counters
Get-NetAdapterStatistics | Format-List Name,ReceivedErrors,OutboundErrors,ReceivedDiscarded,OutgoingDiscarded
# TCP connections by state
Get-NetTCPConnection | Group-Object State | Select-Object Count,Name | Sort-Object Count -DescendingEvent Log Triage
# Critical and Error events in last hour
Get-WinEvent -FilterHashtable @{LogName='System'; Level=1,2; StartTime=(Get-Date).AddHours(-1)} `
| Select-Object TimeCreated, ProviderName, Id, LevelDisplayName, Message | Format-Table -AutoSize7) Linux Guest: Rapid Troubleshooting Commands
# CPU & load
top -b -n 1 | head -n 30
mpstat -P ALL 1 5
pidstat -dru -p ALL 1 5
# Memory pressure
free -m
vmstat 1 5
sudo dmesg | egrep -i 'oom|out of memory'
# Disk I/O
lsblk -o NAME,MODEL,SIZE,ROTA,MOUNTPOINT
iostat -x 1 5
sudo fio --name=randread --filename=/mnt/testfile --bs=4k --rw=randread --size=1G --iodepth=32
# Network
ip -br addr
ss -tupna | head -n 50
iperf3 -c <peer> -P 4 -t 308) VM Connectivity (IAP & OS Login)
# IAP tunnel for SSH when there is no public IP
gcloud compute ssh vm-01 --zone=us-central1-a --tunnel-through-iap
# Serial console for last-resort debugging
gcloud compute instances get-serial-port-output vm-01 --zone=us-central1-a --port 19) Storage Hotfix (Detach/Attach)
# Snapshot then recreate disk from snapshot
gcloud compute disks snapshot vm-01 --zone=us-central1-a --snapshot-names=snap-$(date +%s)
gcloud compute disks create pd-from-snap --source-snapshot=snap-123 --zone=us-central1-a --type=pd-ssd10) Cost Incident: Sudden Spend Spike
- Find new instances/MIG scale-outs; confirm labels for owner/team.
- Check Spot → On-Demand fallbacks around maintenance windows.
- Look for egress bursts from misconfigured NAT or caching disabled.
Security Hardening Checklist (Quick)
- Enable OS Login + 2SV.
- Use dedicated service accounts per app tier.
- Limit default network; least-privilege firewall rules.
- Block project-wide SSH keys unless required.
- Use Confidential VMs for sensitive memory workloads.
- Rotate service account keys; prefer Workload Identity.
- Patch baseline images; automate via MIG rollout policies.
- Encrypt PD with CMEK for regulatory scope.
- Enable VPC Flow Logs for threat hunting.
Migration & Hybrid Patterns
- Lift-and-shift: start with predefined machines; switch to custom after a profiling sprint.
- Replatform to GKE for stateless tiers; keep stateful on VMs.
- Use Interconnect/VPN for steady private connectivity; map DNS for low-risk cutovers.
Operations Automation (SRE-Friendly)
Golden Image Pipeline
- Packer builds base images with agents, CIS hardening, app runtime.
- Template → MIG → canary → regional rollout with surge/batch policy.
Health Signals
- L7 health checks that assert dependency readiness (DB, cache, secrets).
- Custom metrics for queue depth and p95 latency to scale correctly.
Backup & Recovery
- Daily PD snapshots with retention and region diversity.
- Test restores monthly; practice attach-to-helper-VM drill.
FAQ (Concise)
How do I choose between predefined and custom machines?
Start with predefined for speed; switch to custom after measuring CPU saturation, GC pauses, and working-set size. Lock-in gains with templates.
When should I pick Spot/Preemptible?
Any workload that can checkpoint and resume with partial progress: CI, map-reduce, rendering. Keep critical state on PD/Cloud Storage.
Are GPUs always faster?
Not always. Training/inference and massively parallel linear algebra benefit. Profile first; consider CPU-only baselines to compare TCO.
What about Windows licensing?
Use official Windows images to include licensing. BYOL may apply in specific scenarios; confirm eligibility and support terms.
Windows Guest — Admin PowerShell Toolkit (Copy-Paste Ready)
Collect Fast OS Diagnostics
# Save to C:\temp\os-diagnostics.txt (run as admin)
$Out = "C:\temp\os-diagnostics.txt"
New-Item -ItemType Directory -Path (Split-Path $Out) -ErrorAction SilentlyContinue | Out-Null
"===== CPU/Memory =====" | Out-File $Out
Get-Process | Sort-Object CPU -Descending | Select-Object -First 15 `
| Format-Table -AutoSize | Out-String | Out-File $Out -Append
"===== Disks =====" | Out-File $Out -Append
Get-PhysicalDisk | Format-Table -AutoSize | Out-String | Out-File $Out -Append
Get-Disk | Get-Partition | Get-Volume | Format-Table -AutoSize | Out-String | Out-File $Out -Append
"===== Network =====" | Out-File $Out -Append
Get-NetAdapter | Format-Table -AutoSize | Out-String | Out-File $Out -Append
Get-NetAdapterStatistics | Format-Table -AutoSize | Out-String | Out-File $Out -Append
"===== System Errors (2h) =====" | Out-File $Out -Append
Get-WinEvent -FilterHashtable @{LogName='System'; Level=1,2; StartTime=(Get-Date).AddHours(-2)} `
| Select-Object TimeCreated, ProviderName, Id, Message | Out-File $Out -AppendFind Filesystem Bottlenecks
# Find volumes with high latency over 60s
1..20 | ForEach-Object {
$r = (Get-Counter '\PhysicalDisk(*)\Avg. Disk sec/Read','\PhysicalDisk(*)\Avg. Disk sec/Write').CounterSamples
$r | Sort-Object CookedValue -Descending | Select-Object -First 5 | Format-Table -AutoSize
Start-Sleep -Seconds 3
}Network MTU & Path Issues
# Discover max MTU to an endpoint
$tgt = "8.8.8.8"
1..3 | % {ping $tgt -f -l 1472}
# If fragments, reduce payload (e.g., 1430) until successLinux Guest — Quick Bash Toolkit
#!/usr/bin/env bash
set -euo pipefail
echo "===== CPU ====="
mpstat -P ALL 1 5 || true
echo "===== MEM ====="
free -m
vmstat 1 5
echo "===== IO ====="
lsblk -o NAME,MODEL,SIZE,ROTA,MOUNTPOINT
iostat -x 1 5 || true
echo "===== NET ====="
ip -br addr
ss -tupna | head -n 50
echo "===== DMSG (OOM) ====="
dmesg | egrep -i 'oom|out of memory' || trueFive Common Incidents & Resolution Runbooks
Incident 1 — API Error Rate Spike after Deploy
- Check MIG rollout surge/batch; pause if error budget blown.
- Tail app logs; compare old vs new image hash.
- Roll back template; pin traffic via load balancer to healthy subset.
Incident 2 — Disk Throughput Ceiling
- Identify PD type; resize to raise IOPS limit; switch to SSD PD.
- Batch writes and align fs block size; enable TRIM.
- For temp heavy IO, add Local SSD and redirect caches.
Incident 3 — Latency Jump between Two Services
- Check placement policy; co-locate chatty services same zone/rack group.
- Verify MTU & MSS clamping for tunnels; test with iperf3.
- Add connection pooling and tune keep-alive.
Incident 4 — Spot Evictions Hamper Batch
- Checkpoint state to PD/Cloud Storage periodically.
- Use mixed MIG (Spot + On-Demand) with min baseline of On-Demand.
- Spread across zones; relax accelerator constraints if possible.
Incident 5 — SSH/RDP Access Lost
- Use IAP tunnel; check OS Login bindings and IAM.
- Use serial console to reset user or firewall rules via metadata scripts.
- Detach boot disk → helper VM → fix sshd_config / firewall → reattach.
Governance, FinOps & Reliability Tips
- Enforce labels (owner, cost-center, env) via policy and pipelines.
- Use budgets and anomaly alerts tied to messaging channels.
- Codify SLOs (availability and latency) and wire them to autoscaling signals.
- Quarterly right-sizing: compare perf counters vs allocation; refactor into custom machines.
Conclusion
Compute Engine shines when you pair customizable VM shapes with automation and observability. Use custom vCPU/RAM, PD types, GPUs/TPUs, and placement policies to hit performance targets; protect it with IAM, Shielded/Confidential VMs, and VPC controls; and keep costs in check with Spot, sustained use, and right-sizing.