
Multi-cloud architecture: how to run on AWS + GCP without blowing up complexity
Quick summary: Running on both AWS and Google Cloud is powerful — but complexity explodes without rules. This guide gives a clear strategy, pragmatic patterns (Kubernetes portability, IaC, networking), governance, FinOps, security automation and a step-by-step rollout plan so teams can start small and scale. Follow the checklists and trade-offs to avoid common multi-cloud traps.
Estimated reading time: ~18 minutes • SEO-optimized • Word count: 4,000+ words
Why multi-cloud — and why most projects go wrong
Enterprises adopt multi-cloud for a mix of reasons: reduce vendor lock-in, meet regulatory or data-residency constraints, optimize cost by selecting best-of-breed services, or achieve higher resiliency by replicating workloads across providers. All of these are valid, but each introduces operational overhead.
Complexity spikes when teams copy single-cloud patterns to the other cloud without alignment — e.g., using cloud-specific managed services everywhere, inconsistent tagging, divergent CI/CD, and fragmented security policies. This guide helps you set a clear strategy first and then adopt a set of constrained, repeatable patterns so multi-cloud becomes a capability, not a liability.
1. Define a clear multi-cloud strategy
Start with a simple question: Why are you using more than one cloud? The answer drives technical trade-offs.
- Resiliency & DR: Cross-cloud redundancy for critical workloads (active-passive or active-active).
- Regulatory & Data residency: Certain data may legally require a specific region/provider.
- Best-of-breed services: Use GCP for analytics/Machine Learning and AWS for certain operational services, for example.
- Commercial leverage: Use bargaining power against a single CSP.
- Latency & geography: Run services in the cloud nearest to your users/partners.
Deliverables from strategy
- A prioritized list of workloads with their recommended primary cloud and an interoperability plan.
- Governance model: who decides workload placement and who pays for what.
- Risk matrix: data-in-transit, data residency, failover procedures and RTO/RPO targets.
- FinOps targets: acceptable monthly spend variance, guardrails and reporting cadence.
2. Adopt a cloud-agnostic design approach
Design your apps for portability. That doesn't mean avoiding platform services entirely — it means being deliberate about where and why you use them. The most practical approach is:
- Use containerized microservices as the primary deployment unit.
- Model environment-specific extensions as thin adapters or sidecars (e.g., cloud-specific logging or IAM connectors).
- Keep business logic decoupled from infrastructure APIs by using service abstraction layers and well-defined interfaces.
Kubernetes as the universal runtime
Kubernetes (EKS on AWS and GKE on GCP) is the most widely adopted abstraction to reduce operational differences between clouds. Use Kubernetes-native patterns (ConfigMaps, Secrets, Operators) and consider a GitOps flow for cluster lifecycle and app deployments. When migrating workloads from one managed Kubernetes to another, follow the vendor guidance to reduce friction and cost — for example Google Cloud provides specific guidance for migrating EKS workloads to GKE.
Design rule: treat cloud-managed services (e.g., managed DBs, serverless glue) as “opinionated” — use them where the value significantly outweighs the portability cost.
3. Use Infrastructure as Code (IaC) to standardize deployments
Use a consistent IaC toolset so teams can provision resources across providers from a single source of truth. Options include:
- Terraform: the de-facto multi-cloud IaC tool with broad provider support and mature module ecosystems.
- Crossplane: Kubernetes-native control-plane for provisioning cloud resources via CRDs for true GitOps-style infra.
- Pulumi: use conventional languages (TypeScript, Python) if you prefer general-purpose languages over HCL.
Practical IaC patterns
- One repo per environment type (prod/staging) + modules: Reuse modules for common patterns (VPC, networking, IAM).
- Provider-specific modules: isolate provider-specific resources behind modules that expose standardized inputs.
- State management: centralize state in a backend that supports locking (e.g., Terraform Cloud, S3 + DynamoDB locks, or a supported remote state manager).
- Policy-as-code: gate merges with policy checks (e.g., Open Policy Agent, Sentinel) to prevent drift and enforce tagging.
Adopt conventions for naming, tagging and lifecycle so cost and governance tools can read consistent metadata across clouds.
4. Leverage multi-cloud networking solutions
One of the practical parts of multi-cloud is connecting networks reliably and securely. Options vary in complexity and cost:
Direct cloud-to-cloud connectivity
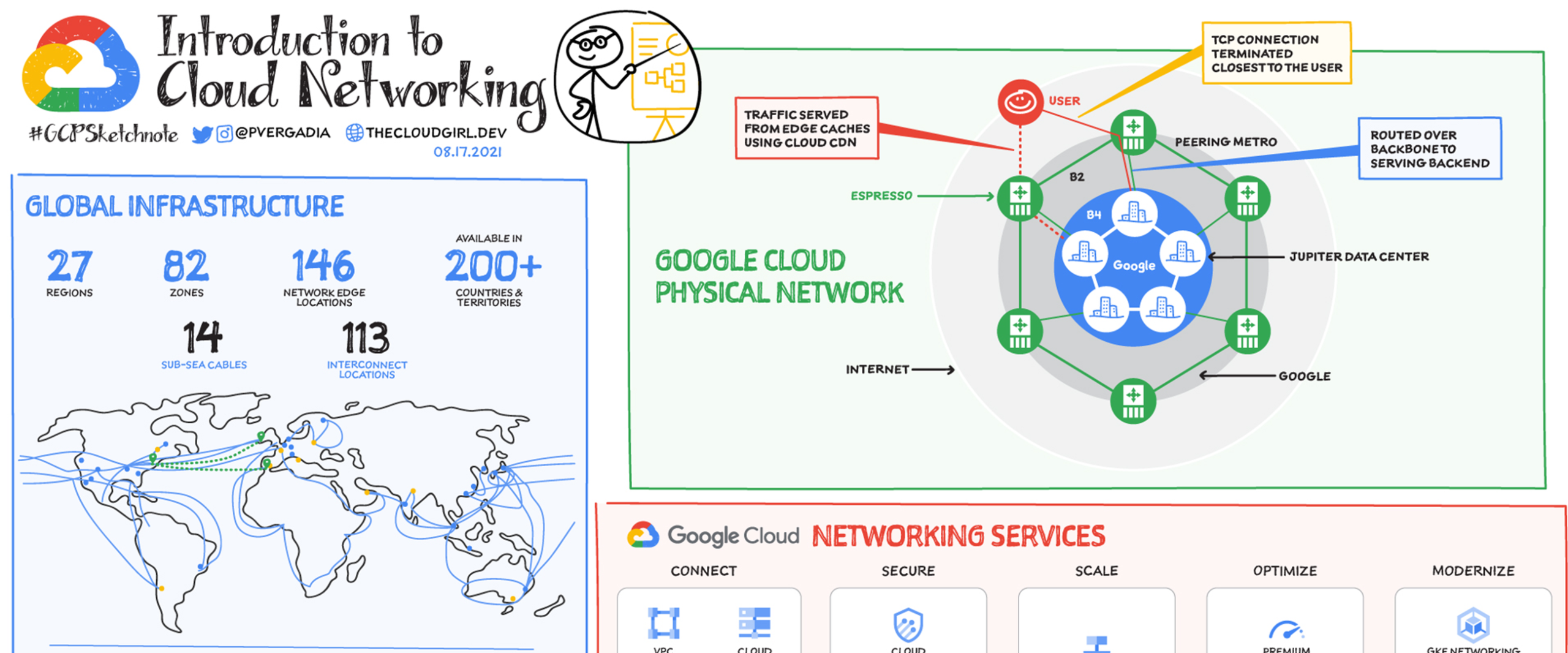
Both vendors offer official ways to connect clouds: high-availability VPNs, direct interconnects, and partner-based private connections. Google Cloud documents patterns and tutorials for connecting GCP with other CSPs (including AWS) and shows how to build HA VPN connections and transit architectures.
Transit / Hub-and-spoke vs SD-WAN
- Transit hub: Use a hub-and-spoke model (Transit Gateway on AWS, Cloud Router / Network Connectivity Center on GCP) to centralize routing and security.
- SD-WAN: For hybrid and global enterprises, a managed SD-WAN (Cisco, VMware, or third-party providers) simplifies policy-based routing and reduces egress and duplication.
- Third-party cloud networking fabrics: Consider offerings from cloud networking vendors that provide a consistent overlay across CSPs.
Minimize egress costs
Network egress is one of the biggest cost drivers in multi-cloud. Keep heavy data processing where the data lives; use cross-cloud replication sparingly and use caches or multi-region object gateways to reduce cross-cloud traffic.
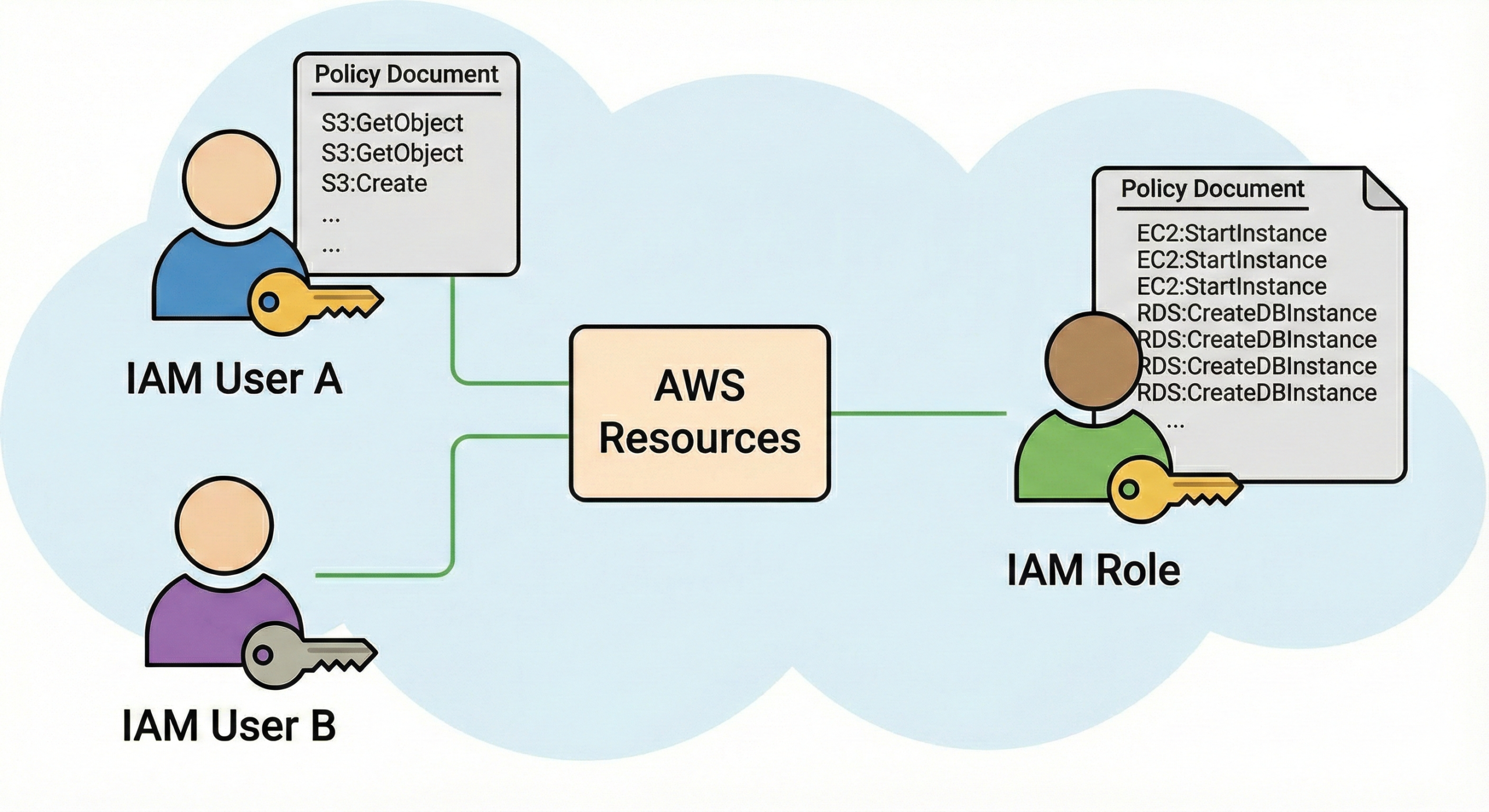
5. Centralized Identity and Access Management (IAM)
Inconsistent IAM is an operational hazard. Federate identity with a central identity provider so teams don't maintain separate users, credentials, and policies in each cloud.
- Use SAML/OIDC federation with enterprise IdPs (Okta, Ping, Azure AD / Entra ID) to centralize authentication and simplify SSO.
- Define cross-cloud roles and role mappings; avoid ad-hoc cloud-native accounts with long-lived keys.
- Use short-lived credentials and workload identity (e.g., AWS IAM Roles for Service Accounts, GCP Workload Identity) to reduce risk from leaked keys.
Secrets management
Centralize secrets via tools that can integrate across clouds (HashiCorp Vault, AWS Secrets Manager federated via secure flows, or a Kubernetes-native secrets operator backed by a central vault) to keep rotation, auditing and policy consistent.
6. Unified monitoring and logging
Cross-cloud visibility is mandatory for troubleshooting and for cost accountability. Use platforms that support multi-cloud telemetry (metrics, logs, traces).
Commercial SaaS platforms such as Datadog provide turnkey multi-cloud monitoring with broad integrations for AWS and GCP to centralize metrics, logs, APM and cost data. Use these platforms to create unified dashboards and alerting rules.
Open-source stack
If you prefer OSS, standardize on Prometheus for metrics, Loki/Fluentd for logs, and Jaeger/OTel for traces, then build a Grafana dashboard that aggregates all data sources.
Tracing and correlation
Adopt consistent distributed tracing and correlation IDs across services so span data can be stitched across clouds.
7. Centralize security and compliance
Enforce a consistent security posture by combining cloud-native tooling with central policy engines:
- Automate security posture checks using OPA, AWS Config, and GCP Organization Policy Service.
- Use a central Security Information and Event Management (SIEM) or cloud-native security consoles aggregated into one view.
- Secrets, encryption keys and KMS: determine whether keys live centrally (HSM-backed) or in each cloud and define an access policy.
Security automation
Automate routine remediation (e.g., disabling public S3 buckets, enforcing TLS) with Infrastructure as Code and policy-as-code so human error is reduced.
8. Unified data management and storage strategy
Data is the trickiest part of multi-cloud. Choose patterns based on consistency, latency, and cost requirements.
Object storage and replication
Multi-cloud object gateways and S3-compatible layers such as MinIO let you present a unified namespace and replicate objects between Amazon S3 and Google Cloud Storage. When you need a single consistent endpoint with high performance and portability, distributed S3-compatible solutions are a practical choice.
Databases
Use managed DBs where portability is not a primary concern — but if you need cross-cloud active-active or easy relocation, evaluate purpose-built multi-cloud databases (CockroachDB, MongoDB Atlas, etc.). CockroachDB is designed to run across multiple providers; Google Spanner is tightly integrated with GCP and is not portable. Choose based on your transactional needs and replication model.
Analytics & data gravity
Where heavy analytics happens, bring compute to the data. If your analytics lives on BigQuery or a cloud data warehouse, avoid moving terabytes across clouds frequently — instead consider cross-cloud access patterns or federated queries.
9. Multi-cloud CI/CD pipeline
Design pipelines that can deploy to both AWS and GCP depending on the target environment. Options:
- GitHub Actions — reusable workflows and environment-specific job matrices for multi-target deploys.
- Jenkins or GitLab CI — centralized orchestration to trigger cloud-specific deploy stages and IaC runs.
- Promote artifacts across environments (artifact registry, container registry) and use signed images with vulnerability scanning in the pipeline.
Best practices
- Keep the pipeline declarative and idempotent.
- Run integration tests against a common test environment that simulates cross-cloud dependencies.
- Store artifacts and policy-metadata in central registries (Container Registry, Artifact Registry, or an enterprise registry).
10. Consistent API gateway and service mesh
Service meshes and API gateways simplify traffic management and policies across clusters and clouds:
- Service mesh (Istio, Linkerd, AWS App Mesh) for observability, retries, mTLS and traffic shifting.
- API gateway to consolidate north-south traffic and enforce authN/authZ rules.
Use these tools to centralize policy enforcement and reduce per-cluster customizations.
11. Disaster Recovery and High Availability design
Cross-cloud DR strategies can be active-passive (primary in one cloud, failover in another) or active-active for critical services. Key design choices:
- Define RTO and RPO precisely per workload.
- Use asynchronous replication for cross-cloud data to avoid latency coupling.
- Automate failover runbooks and test failovers regularly with canary traffic.
- Control DNS failover via health checks and short TTLs to minimize cutover time.
12. Optimize for cost efficiency (FinOps)
Multi-cloud can increase costs if not carefully governed. Establish a FinOps practice that centralizes reporting, budgets and showbacks.
Translate cloud provider terms and metrics into a common taxonomy for meaningful comparisons — the FinOps community has resources for multi-cloud terminology and practices to standardize cost analysis.
Practical FinOps steps
- Implement centralized cost ingestion: export billing to a normalized data lake or use a SaaS cost platform.
- Tagging & ownership: mandatory tags, resource owners, and automated enforcement.
- Use discounts and reservations where appropriate but weigh portability trade-offs.
- Guardrails: automated policies to prevent runaway resources and alerts for unusual spend.
13. Train teams and evolve organization design
Multi-cloud requires multi-skilled teams. Options:
- Federated model: cloud-platform teams for each provider + centralized platform team for shared tooling.
- Platform team-led: single platform team provides self-service landing zones and standards; product teams consume via APIs.
Invest in training (EKS & GKE specifics, Terraform/Crossplane, networking, FinOps). Keep runbooks, run periodic cross-cloud drills, and rotate on-call responsibilities so knowledge spreads.
14. Governance and tagging standardization
Use a governance framework that includes naming, required tags, allowed resource types, and cost allocation rules. Enforce this through IaC, policy-as-code and automated checks in CI/CD.
Minimum tag set
Examples: owner, project, environment, cost-center, compliance. Enforce via pre-merge checks and pipeline tests.
15. Implementation plan: start small, scale gradually
Multi-cloud is a marathon — not a sprint. Use a phased rollout:
- Pilot workload: pick a low-risk workload (e.g., an analytics pipeline on GCP + web frontend on AWS).
- Prove patterns: validate IaC modules, CI/CD flow, networking and monitoring.
- Harden security: apply policy-as-code and secrets management across the pilot.
- Scale: add more workloads and automate cross-cloud failover and cost reporting.
Checklist for pilot success
- Clear owner and success criteria
- Documented runbooks and rollback procedures
- Automated observability and alerting in place
- Cost tracking enabled and baseline measured
16. Patterns, examples and trade-offs (practical snippets)
Workload placement decision matrix
Keep a simple matrix that maps workload characteristics to the recommended cloud:
- High-throughput analytics: GCP (BigQuery) or where data is cached — avoid moving data.
- Event-driven backend: AWS (Lambda) if using deep AWS-specific ecosystem — otherwise containerize and run on EKS/GKE.
- Transactional OLTP: Use databases that meet consistency & latency needs — consider CockroachDB for cross-cloud transactional requirements.
Example: Cross-cloud object replication (pattern)
Use an S3-compatible gateway (MinIO) or scheduled replication jobs to mirror objects between S3 and GCS. This maintains a local copy in each cloud and reduces egress by serving traffic from the nearest location. MinIO’s approach gives you S3 compatibility and a unified namespace for cloud native workloads.
Example: Kubernetes portability checklist
- Use images with OS-agnostic base layers
- Do not rely on cloud-native services in pod specs; use adapters
- Abstract storage with CSI drivers and ensure your CSI drivers are supported in both clouds
- Manage cluster lifecycle with a GitOps flow and standardized cluster profiles
17. Common pitfalls and how to avoid them
- Over-abstracting: Trying to hide cloud differences entirely leads to weak use of cloud features. Use abstraction only where it reduces risk or cost.
- Ignoring data gravity: Moving large datasets between clouds without a plan is expensive and slow.
- Fragmented ownership: No clear owner for cross-cloud services — results in duplicated effort and security gaps.
- No FinOps practice: Multi-cloud without cost governance leads to runaway bills.
18. Multi-cloud readiness checklist (quick)
- Business case & workload placement completed
- IaC modules and remote state established
- Network connectivity & egress plan validated
- Centralized identity & secrets in place
- Monitoring/observability integrated across clouds
- FinOps baseline and tagging enforced
- DR & failover tested
19. Conclusion — keep the scope small and the patterns strict
Multi-cloud can deliver strategic benefits — resiliency, geographic reach, and best-of-breed services — but only if you constrain complexity with a clear strategy, consistent patterns, and automation. Start with one or two pilot workloads, enforce IaC and policy-as-code, centralize IAM and observability, and run a FinOps practice to keep costs in check. Repeatable patterns — Kubernetes as an abstraction layer, centralized secrets, and a policy-driven pipeline — make multi-cloud manageable at scale.
- A one-page architecture diagram (SVG) of a recommended AWS+GCP hub-and-spoke with Kubernetes clusters, MinIO edge, and central monitoring.
- A Terraform module scaffold for cross-cloud VPC + Kubernetes cluster creation.
- A sample GitHub Actions workflow that deploys to both EKS and GKE with Terraform & Helm.

Your article helped me a lot, is there any more related content? Thanks!