
Amazon S3 (Simple Storage Service): Object Storage for Backups, Static Websites, and Data Lakes
This comprehensive guide covers Amazon S3 fundamentals, security, cost optimization, data lakes, static website hosting, compliance, and hands-on troubleshooting with AWS CLI & PowerShell.cloudknowledge.in.
Introduction: Why Amazon S3 Matters
Amazon S3 is a massively scalable, highly durable object storage service designed to store and retrieve any amount of data from anywhere on the web. S3 is the foundation for modern backups, static website hosting, content distribution, media archives, analytics, and data lakes. It delivers 99.999999999% (11 nines) durability and up to 99.99% availability (S3 Standard), with a pay-as-you-go model that aligns cost to usage.
Unlike block or file storage, S3 stores data as objects in buckets. Each object has a key (path-like name), data, and rich metadata. That design makes S3 ideal for unstructured datasets (images, logs, video, ML features) and metadata-driven workflows that power modern cloud architectures.
The Object Storage Model: Keys, Buckets, and Metadata
- Bucket: Global namespace container that groups objects, policies, encryption, and logging.
- Object: Data + metadata addressed by a unique object key (e.g.,
logs/2025/11/01/app.json). - Metadata: System (size, ETag, content type) + custom (tags, attributes for lifecycle and analytics).
- Eventing: Object changes can trigger serverless actions via Lambda, SQS, or SNS.
Design object keys for natural partitioning and parallelism. Use prefix patterns (e.g., date-based or hash sharding) to maximize request concurrency and consistent performance.
S3 Buckets: Practical Design & Naming
Buckets are globally unique. Use DNS-compliant names and encode environment, region, data class, and lifecycle intent:
acme-prod-ap-south-1-logs-immutable. Separate data domains into distinct buckets for clearer policy boundaries
and governance.
- Enable Block Public Access unless hosting a public static site.
- Turn on Versioning for rollback, replication, and Object Lock.
- Enforce encryption (SSE-S3 or SSE-KMS) with a bucket policy denial for unencrypted puts.
- Attach least-privilege IAM and bucket policies; avoid legacy ACLs.
- For private access, use VPC endpoints (Gateway/Interface) and restrict to them.
Durability & Availability: 11 Nines of Confidence
S3 Standard is engineered for 11 nines durability and multi-AZ resilience. Availability depends on class (e.g., 99.99% for Standard). For regional events or compliance, add Cross-Region Replication (CRR) to another AWS Region.
Storage Classes: Align Cost to Access
- Standard: Default, low latency, high throughput.
- Intelligent-Tiering: Auto-tiers across frequent/IA/archive tiers without performance impact.
- Standard-IA / One Zone-IA: Lower cost for infrequent access; One Zone trades AZ redundancy for price.
- Glacier Instant Retrieval: Archive with instant retrieval for rare but urgent reads.
- Glacier Flexible Retrieval: Minutes-to-hours retrieval; cheaper for cold data.
- Glacier Deep Archive: Lowest price, hours-level retrieval.
Use lifecycle transitions and expirations to move data as it ages, and Storage Lens to monitor usage and optimize cost at the account/Org level.
Versioning & Lifecycle Policies
Versioning preserves prior object states and enables MFA Delete for safety. Lifecycle policies automate transitions (e.g., Standard → IA → Glacier) and deletion schedules for compliance and cost control.
{
"Rules": [{
"ID": "logs-tiering",
"Filter": { "Prefix": "logs/" },
"Status": "Enabled",
"Transitions": [
{ "Days": 30, "StorageClass": "STANDARD_IA" },
{ "Days": 90, "StorageClass": "GLACIER" }
],
"Expiration": { "Days": 3650 }
}]
}Security & Access Management: IAM, Bucket Policies, ACLs
Apply least privilege with AWS IAM roles and policies. Use bucket policies to enforce encryption, deny insecure transport, and restrict to VPC endpoints. Keep Block Public Access on globally. Use ACLs only for legacy edge cases.
{
"Version": "2012-10-17",
"Statement": [
{ "Sid": "DenyInsecureTransport",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": ["arn:aws:s3:::acme-prod-logs","arn:aws:s3:::acme-prod-logs/*"],
"Condition": { "Bool": { "aws:SecureTransport": "false" } }
},
{ "Sid": "DenyUnEncryptedObjectUploads",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::acme-prod-logs/*",
"Condition": { "Null": { "s3:x-amz-server-side-encryption": "true" } }
}
]
}Encryption: At Rest & In Transit
- SSE-S3: Simplest—S3 manages keys.
- SSE-KMS: Use AWS-managed or CMKs for auditability and granular access control.
- Client-side: Encrypt before upload if you own key lifecycle.
Enforce TLS with a deny-non-TLS bucket policy, and consider KMS key policies scoped to required roles only.
Backups & Disaster Recovery
S3 is a universal target for database/server backups via AWS Backup, partner tools, or native exports. Harden with Object Lock (Compliance or Governance mode), Versioning, and replication. Regularly test restores.
Static Website Hosting on S3
- Create a public website bucket (or use CloudFront for private origin access).
- Upload HTML/CSS/JS; set index and error docs.
- Prefer CloudFront for HTTPS, custom domains, caching, and origin access control.
Remember: S3 website endpoints differ from REST endpoints. Use CDN best practices (cache headers, invalidations) and least privilege origins.
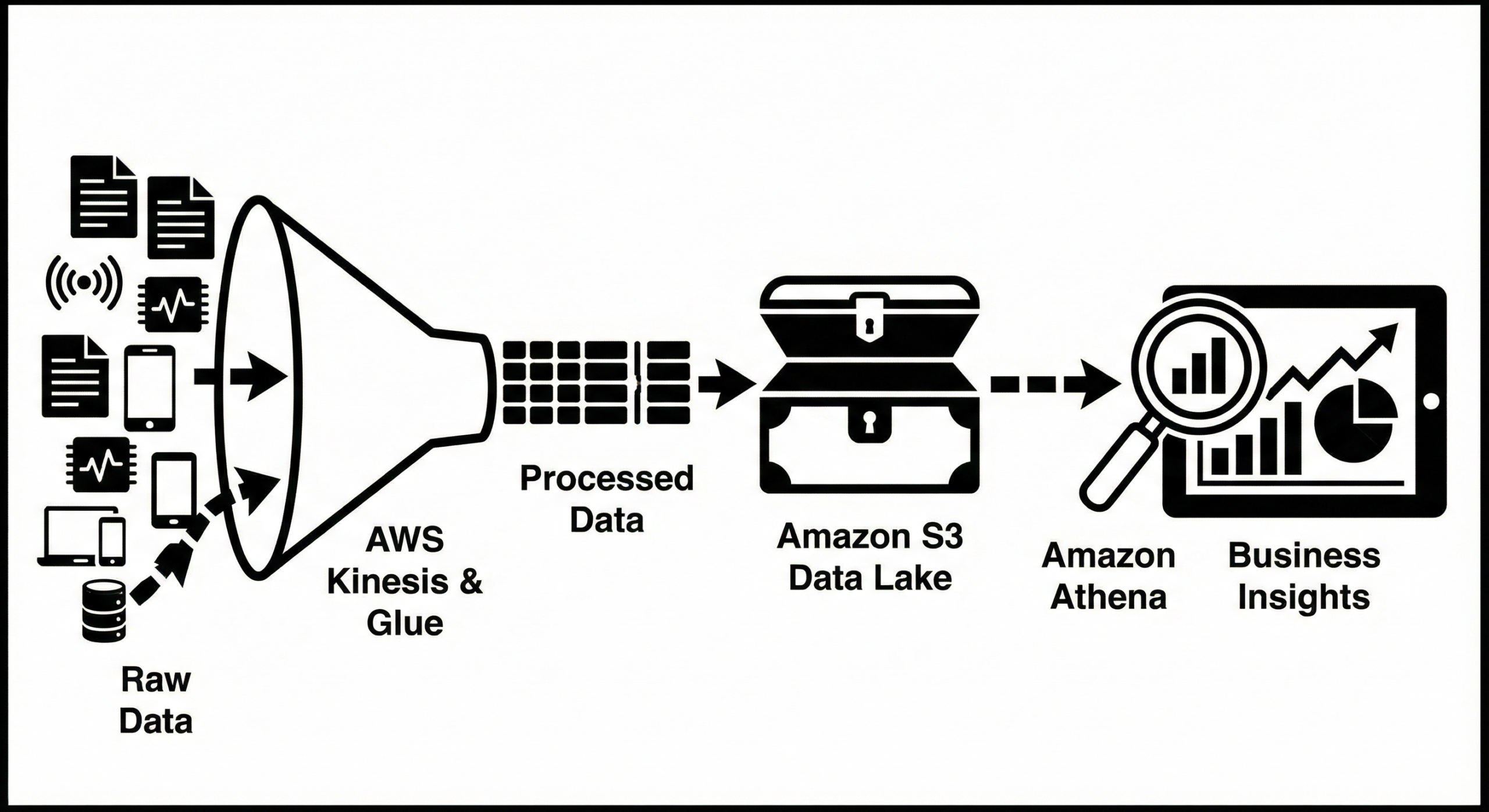
Data Lakes on S3: Analytics-Ready Architecture
Use S3 as the central data layer and connect Glue (catalog, ETL), Athena (SQL on S3), EMR, Redshift Spectrum, and SageMaker. Partition by date/org/app; store data in columnar formats (Parquet/ORC) to minimize scan costs. Govern with Lake Formation.
- Use consistent partitions (e.g.,
dt=YYYY-MM-DD). - Prefer Parquet for compression + predicate pushdown.
- Register tables in Glue Data Catalog; query with Athena.
- Secure with IAM, Lake Formation permissions, and column-level controls.
Object Lock & Compliance
Object Lock enables WORM (write once, read many) for regulatory compliance (e.g., SEC 17a-4). Choose Compliance (immutable) or Governance (privileged overrides) and set legal holds where required. Pair with Versioning and scoped KMS keys.
Replication: Cross-Region & Same-Region
CRR adds geo-redundancy and helps sovereignty requirements. SRR separates prod/analytics or hot/cold copies. Replicate specific prefixes/tags, include delete markers if desired, and monitor replication metrics.
Event Notifications: Automate With Lambda, SQS, SNS
Trigger downstream processing when objects are created or removed—e.g., image thumbnails, log parsing, data quality checks. Use dead-letter queues and idempotent handlers to avoid reprocessing issues.
Performance & Scalability
- S3 scales horizontally for high request rates; no need to pre-shard buckets.
- Design keys for parallelism; avoid extreme hot prefixes during spiky workloads.
- Use multi-part uploads for large objects; tune part size for throughput.
- Leverage S3 Transfer Acceleration or Multi-Region Access Points for global ingest.
Cost Optimization Tactics
- Turn on Intelligent-Tiering for datasets with unpredictable access.
- Right-size lifecycle transitions and expiration for logs and archives.
- Compress and convert to Parquet for analytics.
- Use Storage Lens to surface unused data and orphaned prefixes.
- Clean up incomplete multipart uploads and non-current versions.
Monitoring & Logging
Enable CloudTrail (data events for S3), S3 Server Access Logging or CloudTrail Lake for activity analysis. Export metrics to CloudWatch (requests, bytes, 4xx/5xx) and build alarms on error rates, replication backlogs, and cost anomalies.
Troubleshooting Playbooks (AWS CLI & PowerShell)
Prerequisites
- AWS CLI v2 configured (
aws configure). - AWS Tools for PowerShell installed (
Install-Module -Name AWSPowerShell). - Use IAM roles with least privilege; prefer temporary credentials.
1) “Access Denied” on GetObject/PutObject
Quick checks: TLS enforced? Bucket policy denies? KMS permissions missing? VPC endpoint policy blocking?
AWS CLI: who am I & what can I do?
# Identity & region
aws sts get-caller-identity
aws configure list
# Test object read/write with explicit SSE header
aws s3api get-object --bucket acme-prod-logs --key test/readme.txt /tmp/readme.txt
aws s3api put-object --bucket acme-prod-logs --key test/putcheck.txt --body ./localfile.txt \
--server-side-encryption AES256
# If using KMS key:
aws s3api put-object --bucket acme-prod-logs --key test/kmscheck.txt --body ./localfile.txt \
--server-side-encryption aws:kms --ssekms-key-id <key-arn>PowerShell (AWS Tools):
# Identity
Get-STSCallerIdentity
# Read object
Read-S3Object -BucketName 'acme-prod-logs' -Key 'test/readme.txt' -File 'C:\Temp\readme.txt'
# Write object with SSE-S3
Write-S3Object -BucketName 'acme-prod-logs' -Key 'test/putcheck.txt' -File 'C:\Temp\localfile.txt' `
-ServerSideEncryption 'AES256'
# Write with SSE-KMS
Write-S3Object -BucketName 'acme-prod-logs' -Key 'test/kmscheck.txt' -File 'C:\Temp\localfile.txt' `
-ServerSideEncryption 'aws:kms' -ServerSideEncryptionKeyManagementServiceKeyId '<key-arn>'Policy spot checks:
# Get bucket policy
aws s3api get-bucket-policy --bucket acme-prod-logs --query Policy --output text | jq .
# Get KMS key policy & grants
aws kms get-key-policy --key-id <key-arn> --policy-name default | jq .
aws kms list-grants --key-id <key-arn> | jq .- Bucket has “Deny non-TLS” and the client used HTTP or a proxy terminating TLS.
- Bucket denies puts without SSE headers; add
--server-side-encryption. - KMS key policy doesn’t trust the role; update policy or add a grant.
- VPC endpoint policy restricts actions; allow required S3/KMS APIs.
2) Slow Uploads/Downloads or Multipart Failures
# Force multipart, tune part size, increase concurrency (AWS CLI v2)
aws s3 cp bigfile.bin s3://acme-prod-raw/ --expected-size 100GB --no-progress
# Use Transfer Acceleration if bucket enabled
aws s3 cp bigfile.bin s3://acme-prod-raw/ --endpoint-url https://acme-prod-raw.s3-accelerate.amazonaws.com# PowerShell: multipart handled by Write-S3Object; adjust ServicePointManager for concurrency if needed
[System.Net.ServicePointManager]::DefaultConnectionLimit = 64
Write-S3Object -BucketName 'acme-prod-raw' -Key 'big/bigfile.bin' -File 'C:\Data\bigfile.bin'3) “No Such Key” or Listing Inconsistencies
Verify exact key, prefix, and region. Check lifecycle expirations and replication status.
# List with prefix and versions
aws s3api list-object-versions --bucket acme-prod-raw --prefix logs/2025/11/01/ | jq '.Versions[] | {Key,VersionId,IsLatest,LastModified}'4) Replication Not Working
- Both buckets versioned? Correct IAM role? KMS permissions in source & destination?
- Object meets filter (prefix/tags)? Check replication metrics/events.
# Describe replication
aws s3api get-bucket-replication --bucket acme-prod-raw | jq .
# Test replication by uploading a tagged object that matches the rule
aws s3api put-object --bucket acme-prod-raw --key replicate/test.txt --body ./test.txt \
--tagging "env=prod"5) Audit: Who Touched This Object?
Enable CloudTrail data events for S3. Then query for GetObject/PutObject/DeleteObject on keys of interest.
# Lookup CloudTrail events for a bucket/key
aws cloudtrail lookup-events --lookup-attributes AttributeKey=ResourceName,AttributeValue=acme-prod-raw \
--max-results 50 | jq '.Events[].CloudTrailEvent' | jq -r '. | fromjson | {eventTime,eventName,userIdentity,requestParameters}'6) Cost Spike Investigation
- Check BytesDownloaded and 4xx/5xx metrics per bucket.
- Analyze access logs or CloudTrail data events for unusual actors/prefixes.
# Find largest prefixes quickly (estimation via inventory or ls --summarize)
aws s3 ls s3://acme-prod-raw/ --recursive --human-readable --summarize | tail -n 50
# Storage Lens (org-level) will expose growth and orphaned data trends.PowerShell Guardrails for Safe Bulk Operations
# Safety: block delete unless a confirm flag is passed
param([switch]$ConfirmDelete)
$Bucket = 'acme-prod-raw'
$Prefix = 'staging/'
# List objects
Get-S3Object -BucketName $Bucket -KeyPrefix $Prefix |
Select-Object Key, LastModified, Size | Format-Table -AutoSize
if ($ConfirmDelete) {
Write-Host "Deleting objects under $Prefix ..."
Get-S3Object -BucketName $Bucket -KeyPrefix $Prefix | ForEach-Object {
Remove-S3Object -BucketName $Bucket -Key $_.Key -Force
}
} else {
Write-Warning "Run with -ConfirmDelete to actually delete."
}Governance: Access Points, VPC Endpoints, and Controls
- S3 Access Points simplify per-application access with custom policies.
- VPC Gateway/Interface Endpoints keep traffic on the AWS backbone and allow endpoint policies.
- Use Organization SCPs to prevent risky actions (public buckets, disabling versioning, etc.).
Migrations to S3: From On-Prem & Other Clouds
Choose the right path: AWS DataSync for NFS/SMB at scale, S3 Transfer Acceleration for global uploads,
Snowball for petabyte-scale offline transfer, or parallelized aws s3 cp for incremental moves.
Validate with object counts, total bytes, and checksums (ETag for non-multipart; consider --checksum-algorithm).
Hardening Public Static Sites
- Prefer CloudFront with Origin Access (legacy OAI or OAC) so the bucket stays private.
- Set Content-Type metadata and cache headers at upload.
- Automate invalidations on deploy; use immutable asset names (hashes) for long-cache.
Checklists You Can Reuse
Security Checklist
- Block Public Access on by default.
- Versioning + Object Lock (where required).
- Enforce encryption at rest (SSE-S3/KMS) and TLS in transit.
- Restrict by IAM, bucket policy, and VPC endpoints.
- Enable CloudTrail data events + S3 access logs; alert on anomalies.
Cost Checklist
- Lifecycle transitions to IA/Glacier; expire non-current versions.
- Compress/convert to columnar formats for analytics.
- Monitor with Storage Lens and cost anomaly detection.
Data Lake Checklist
- Partition scheme established and documented.
- Parquet/ORC + Glue Data Catalog + Athena.
- Fine-grained data permissions with Lake Formation.
Quick Start: Create a Secure Bucket (CLI)
BUCKET=acme-prod-raw
REGION=ap-south-1
aws s3api create-bucket --bucket $BUCKET --region $REGION --create-bucket-configuration LocationConstraint=$REGION
# Enable versioning
aws s3api put-bucket-versioning --bucket $BUCKET --versioning-configuration Status=Enabled
# Block public access
aws s3api put-public-access-block --bucket $BUCKET --public-access-block-configuration \
BlockPublicAcls=true,IgnorePublicAcls=true,BlockPublicPolicy=true,RestrictPublicBuckets=true
# Default encryption SSE-S3
aws s3api put-bucket-encryption --bucket $BUCKET --server-side-encryption-configuration '{
"Rules":[{"ApplyServerSideEncryptionByDefault":{"SSEAlgorithm":"AES256"}}]}'Inventory & Governance: Find Public Buckets or Unencrypted Objects
# List buckets and check public access block (requires jq)
aws s3api list-buckets --query 'Buckets[].Name' --output text | tr '\t' '\n' | while read b; do
echo "== $b =="
aws s3api get-public-access-block --bucket "$b" --query 'PublicAccessBlockConfiguration' 2>/dev/null || echo "No block config"
done# PowerShell: list unencrypted objects in a prefix (sample)
$Bucket='acme-prod-raw'; $Prefix='uploads/'
Get-S3Object -BucketName $Bucket -KeyPrefix $Prefix | ForEach-Object {
$meta = Get-S3ObjectMetadata -BucketName $Bucket -Key $_.Key -ErrorAction SilentlyContinue
if ($meta -and -not $meta.ServerSideEncryption) {
"{0}`t{1}" -f $_.Key, "NO-SSE"
}
}FAQ
Should I use Intelligent-Tiering for everything? It’s ideal for variable access patterns; for strictly archival data with predictable cold access, Glacier classes may be cheaper.
Do I need multiple buckets per app? Prefer multiple buckets for clearer policy and lifecycle boundaries (logs, raw, curated, public site).
Can I prevent accidental deletes? Enable Versioning, MFA Delete, Object Lock (Governance/Compliance), and use IAM condition keys for MFA on deletes.
Conclusion
Amazon S3 is the dependable backbone for backups, static web hosting, and data lakes. With disciplined design—versioning, lifecycle policies, encryption, replication, and robust monitoring—you’ll achieve strong durability, performance, and predictable cost. Use the CLI and PowerShell playbooks above to troubleshoot access, performance, replication, and cost spikes with confidence.

Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?